
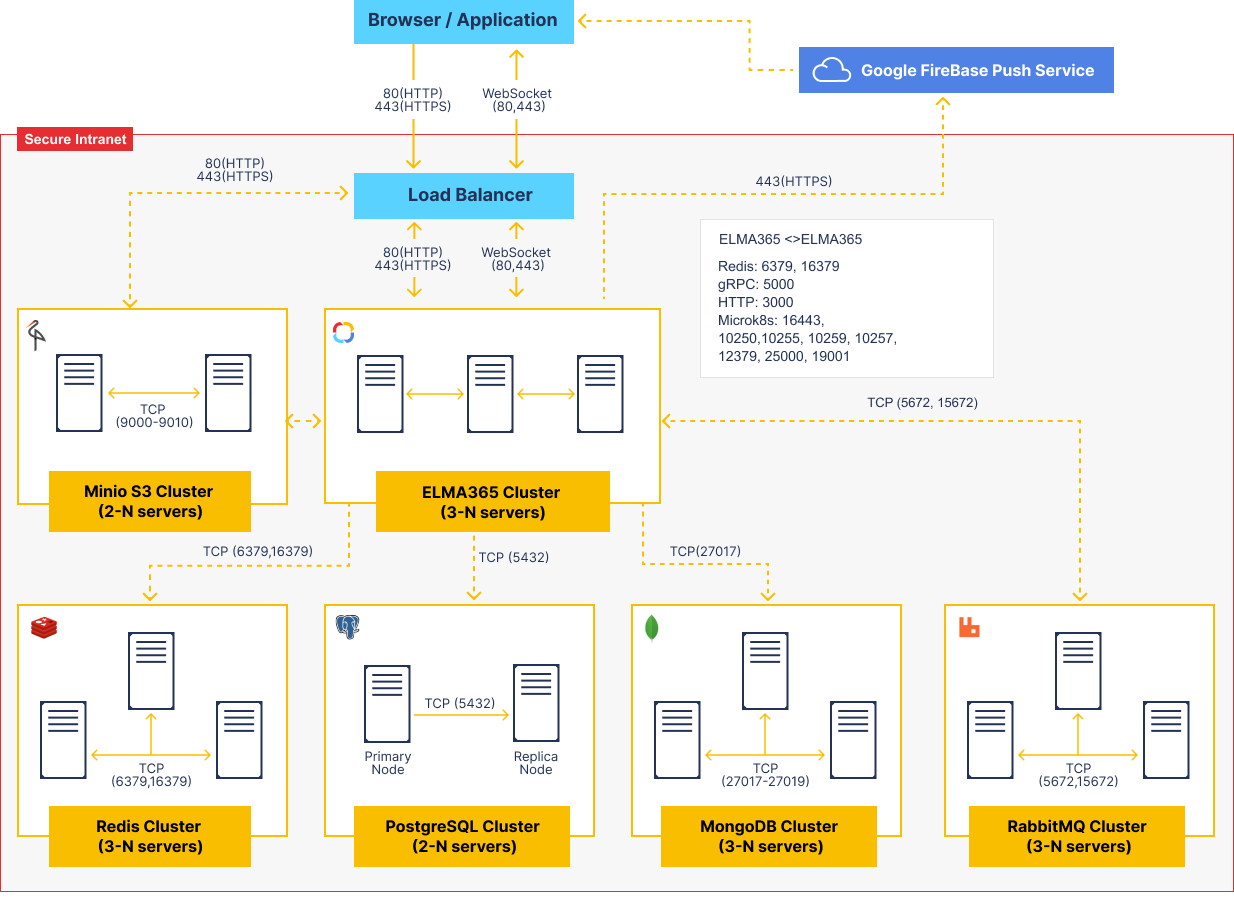
The diagram in this article displays the protocols and ports used for communication between the servers in ELMA365. The information provided on the diagram can also be used for deploying and scaling ELMA365 fault-tolerant clusters.
Data storage services (PostgreSQL, MongoDB, RabbitMQ, Redis, MinIO S3 Deployment) have specific rules of deployment and scaling. You can read more in the Fault-tolerant server architecture section of the System Requirements for ELMA365 Enterprise edition article.
ELMA365 consists of multiple microservices isolated in containers all managed by Kubernetes container orchestrator (the current ELMA 365 On-premises distribution configured to use MicroK8s package, by default).
ELMA365 cluster internal services
auth |
Authorization and groups, users, and org chart management |
balancer |
Multi-tenancy management |
calculator |
Calculating different values in-app items |
chat |
Private and group messages |
collector |
App items read and filter |
convertik |
Office formats to pdf converting |
deploy |
Migration management |
diskjockey |
Files and directories |
docflow |
Document workflow. Approval and review. |
event-bus |
System events monitoring and processing via events bus |
feeder |
Activity stream / channels |
front |
ELMA365 Front end |
integrations |
External integrations |
mailer |
Email management |
main |
API gateway |
messengers* |
Live chats and external messengers management |
notifier* |
Notifications and web-sockets |
processor |
Process management |
picasso |
EDS fingerprint management |
scheduler* |
Schedules, tasks delayed start, time reports |
settings |
User profile and system profile management |
templater |
Text and office documents templater |
vahter |
Users management in a multi-tenancy system |
web-forms |
Web-forms for external systems management |
widget |
Widget management (interface customization) |
worker |
Validating, transpiling, and user scripting |
* - the service cannot be executed in multiple instances
Fault tolerance and scaling of individual services
Distributed Services Architecture allows the solution to scale more flexibly depending on the load profile of the system. By default, all cluster services (except scheduler, notifier, messengers) in the ELMA365 Enterprise cluster are performed in two instances (for ELMA365 Standard edition, in a single instance).
If the cluster combines multiple servers, the microk8s orchestrator tries to evenly distribute the instances of the services among the servers. If either server in the cluster goes down, the orchestrator determines the services interrupted by the failure and replicates them on another server.
It is recommended to run the ELMA365 cluster on at least three nodes to ensure fault tolerance.
Nodes work together, and the cluster permanently checks if all of them are up and running. The server is considered to be “down” if it is unreachable through a network for a specified time. The cluster is fully functional until at least two nodes are up and running.
Adding servers without proper cluster reconfiguration will not automatically solve the problem of increased load. This approach only decreases the chance of service global failure. To leverage cluster throughput you can upgrade any distinct server hardware to a relatively great extent ( handling up to 10000 simultaneous transactions per server).
However, often we can identify a workload bottleneck and eliminate it by scaling the corresponding service. Let’s take a look at the worker script executing service. This service is resource-hungry but runs in parallel very well. If your server is heavily used for server-side script execution then it is reasonable to configure a high replication factor for this service (above 2). The orchestrator will then create additional instances of the service to perform the scripts faster in parallel.
In the same way, you can configure multi-instances parallel execution for any other service. However, to understand what services should be scaled, it is necessary to analyze the workload profile of a particular configuration at a specific time.
Found a typo? Highlight the text, press ctrl + enter and notify us