Вы можете отслеживать ключевые показатели системы в реальном времени, используя дэшборд ELMA365-Overview.
Он состоит из следующих разделов:
- ELMA365;
- ELMA365 – Telemetry;
- Kubernetes Cluster;
- Pods info;
- Nodes info;
- Postgres;
- RabbitMQ;
- MongoDB;
- Cache;
- Ingress;
- Logs;
- Linkerd;
- Kubernetes Events – Stats.
Предварительные настройки для дэшборда «ELMA365‑Overview»
Для корректной работы предварительно установите:
- Prometheus и Grafana — для хранения и отображения данных. Подробнее читайте в статье «Установка средств мониторинга»;
- дополнение DBSExporter — чтобы собирать показатели баз данных. Читайте об этом в статье «Мониторинг баз данных»;
- Kubernetes Event Exporter — для анализа событий Kubernetes-кластера. Подробнее читайте в статье «Мониторинг событий»;
- Loki — для сбора и хранения логов о работе системы;
- Linkerd (опционально) — если вы настраиваете обработку связи между сервисами и хотите отслеживать параметры соединения.
Чтобы активировать сбор метрик бизнес-процессов, в файле values-elma365.yaml включите параметр dashboards.enabled. Подробнее читайте в статье «Мониторинг бизнес-процессов».
После этого данные для дэшборда будут аккумулироваться в хранилище Prometheus и визуализироваться с помощью сервиса Grafana.
Рассмотрим более подробно содержание разделов дэшборда ELMA365-Overview.
Раздел «ELMA365»
В этом разделе представлены графики, которые позволяют оценить стабильность работы системы, скорость обработки запросов и эффективность выполнения скриптов.
Мониторинг системы разделён на два ключевых блока:
- Анализ работы API.
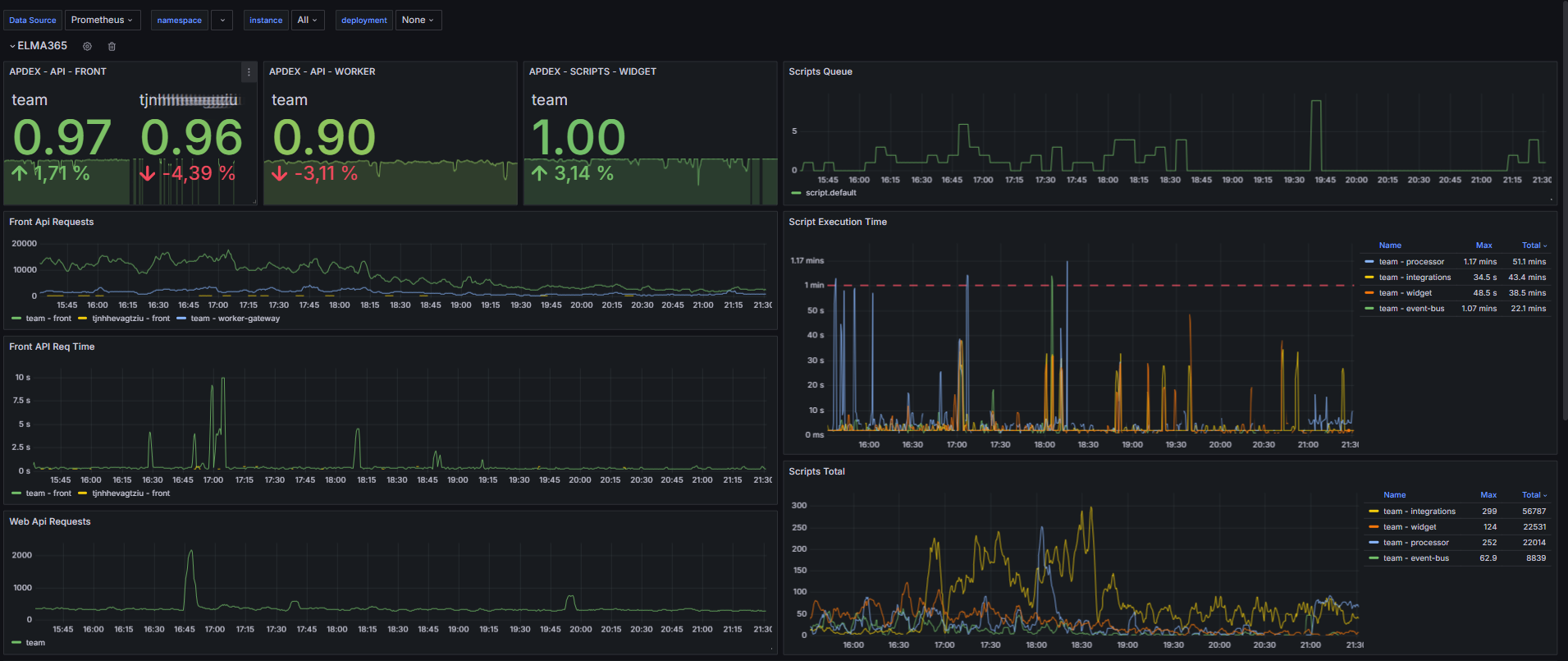
На графиках можно отслеживать, сколько поступает запросов и за какое время они обрабатываются. Если количество запросов не меняется, а длительность их выполнения растёт, проверьте доступность зависимых сервисов и базы данных. Оптимизируйте также запросы к БД.
- Статистика выполнения скриптов.
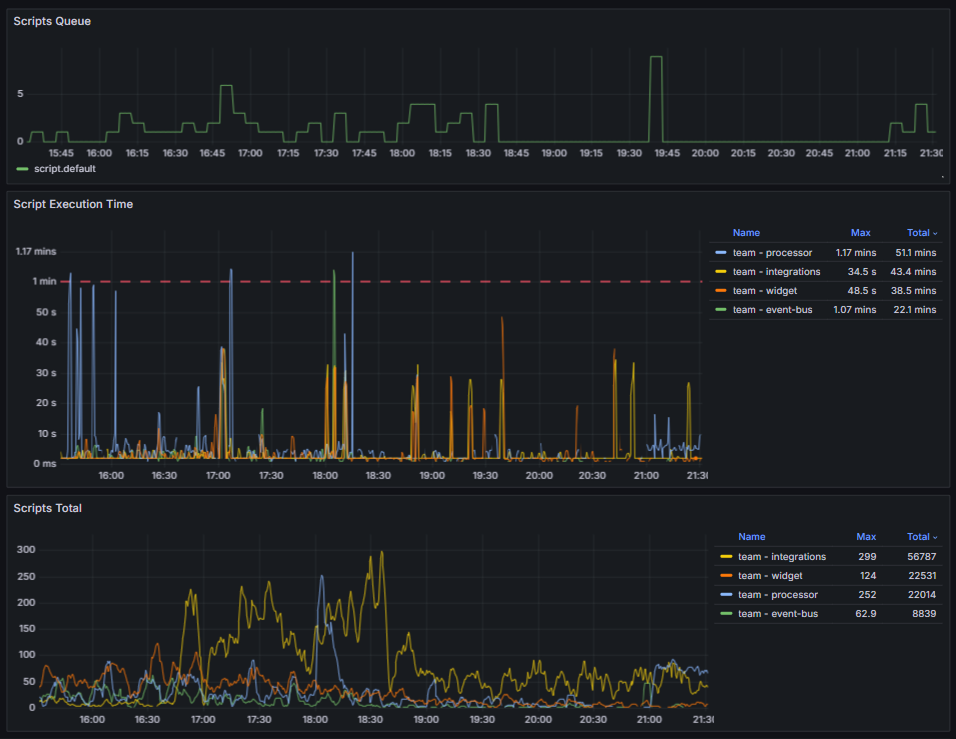
Вы можете отслеживать очередь, время выполнения и общее количество скриптов. На графиках обращайте внимание на общую динамику и резкий рост кривых. Такие скачки могут означать, что скриптов запускается больше обычного или увеличилось время их выполнения. При переполнении очереди проверьте доступность зависимых сервисов и БД. Если время выполнения скриптов постоянно растёт, оптимизируйте их.
Раздел «ELMA365 – Telemetry»
В этом разделе вы можете отследить производительность пользовательских скриптов:
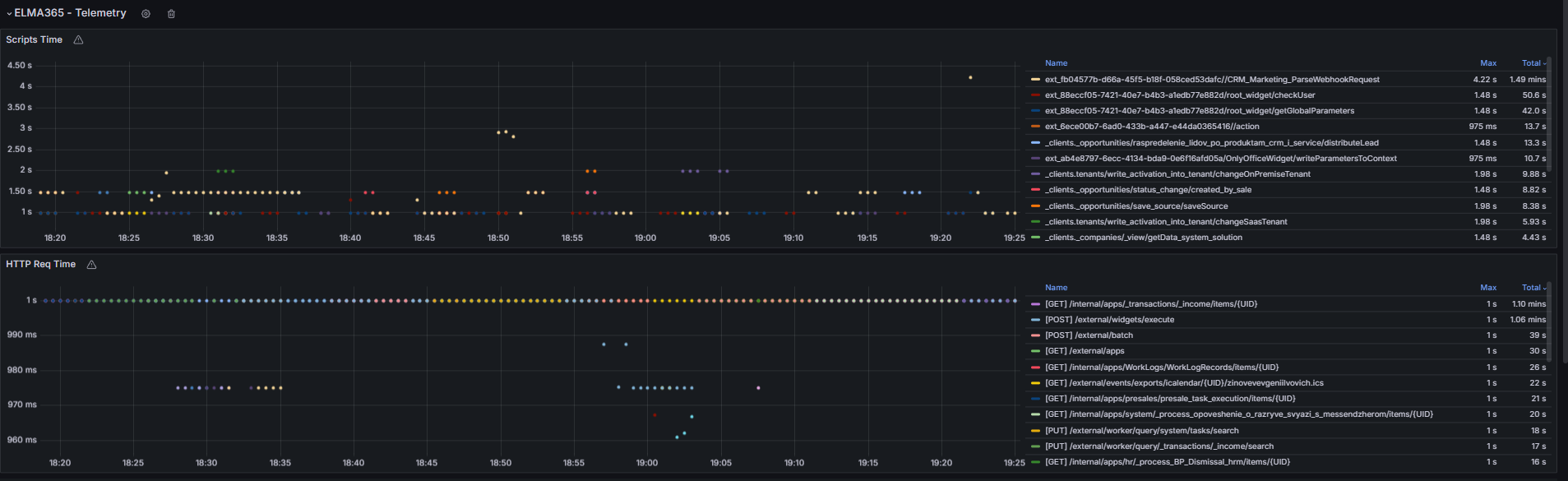
- на графике Script Time — время выполнения скриптов, которое зависит от их логики и реализуемых операций. Определите базовый уровень для типовых скриптов и анализируйте их работу. Признаками снижения производительности являются:
- устойчивый рост времени выполнения скрипта на 30‑50% относительно стандартного значения;
- выполнение более 3‑5 секунд для скриптов с типовым запросом и простой логикой.
Возможные причины неполадок: неоптимальные алгоритмы, рост объёма данных, блокировки;
- на графике HTTP Req Time — время выполнения HTTP‑запросов. Если вы наблюдаете устойчивый рост ошибок, изучите логи Loki.
Раздел «Kubernetes Cluster»
В этом разделе можно оценить состояние управляющих компонентов кластера. Они нужны для работы всех приложений, включая ELMA365. Проблемы на этом уровне могут привести к каскадным сбоям.
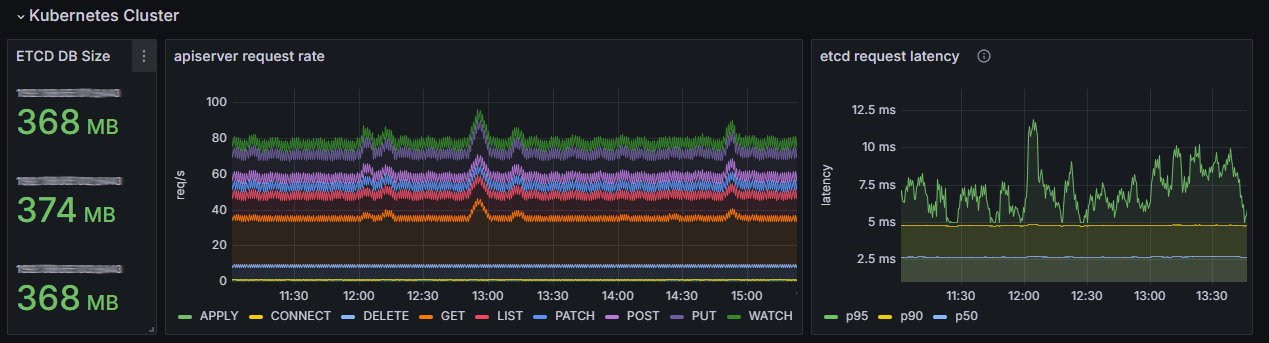
На графиках отображаются следующие данные:
- ETCD DB Size — объём базы данных etcd. Нормой является стабильное значение с плавным ростом, которое соответствует активности в кластере. Для средних кластеров стандартный объём — от сотен МБ до нескольких ГБ.
На возможные проблемы указывают:
- устойчивое приближение к лимиту. По умолчанию он составляет 2 ГБ, но вы можете установить другое значение;
- резкий и необъяснимый рост объёма данных.
Важно: если база данных etcd заполняется более чем на 90% от доступного лимита, она может перейти в режим только для чтения. Это блокирует операции записи в кластере — нельзя создавать или обновлять объекты.
- apiserver request rate — количество запросов к API‑серверу Kubernetes. Нормой является рост числа LIST- и GET‑запросов пропорционально увеличению числа подов, сервисов или запросов от инструментов мониторинга, например Prometheus.
На возможные проблемы указывают резкое падение количества запросов или их устойчивый рост.
- etcd request latency — скорость обработки запросов на стороне etcd. В норме задержка запросов должна быть стабильной и низкой. Для операции wal_fsync p95 (95-й процентиль) на исправном SSD/NVMe диске задержка составляет обычно меньше 15 мс, а p50 — меньше 5 мс.
Отклонением от нормы являются значения: для p95 — больше 100‑500 мс, а для p50 — больше 20 мс. Причиной может быть недостаточная скорость диска, что приводит к задержкам во всём кластере.
Как найти источники нагрузки на etcd
Для стабилизации состояния хранилища etcd выявите компоненты, которые создают аномальную нагрузку на etcd, и оптимизируйте их работу. Для этого:
- Если настройки вашего etcd позволяют посмотреть список всех ключей, получите их с помощью команды:
etcdctl get --prefix / --keys-only
Анализ полученного списка помогает выявить преобладающие типы ключей. По ним можно определить, какой компонент является источником повышенной нагрузки.
- Проанализируйте метрики apiserver_request_total, которые доступны в системе мониторинга Grafana. Высокие показатели количества запросов к определённым компонентам помогают определить потенциальные источники нагрузки. Часто она возникает из-за чрезмерной активности инструмента Prometheus, операторов и контроллеров, повторяющихся перезапусков kubelet.
Раздел «Pods info»
На этих графиках отслеживайте состояние подов приложения ELMA365:
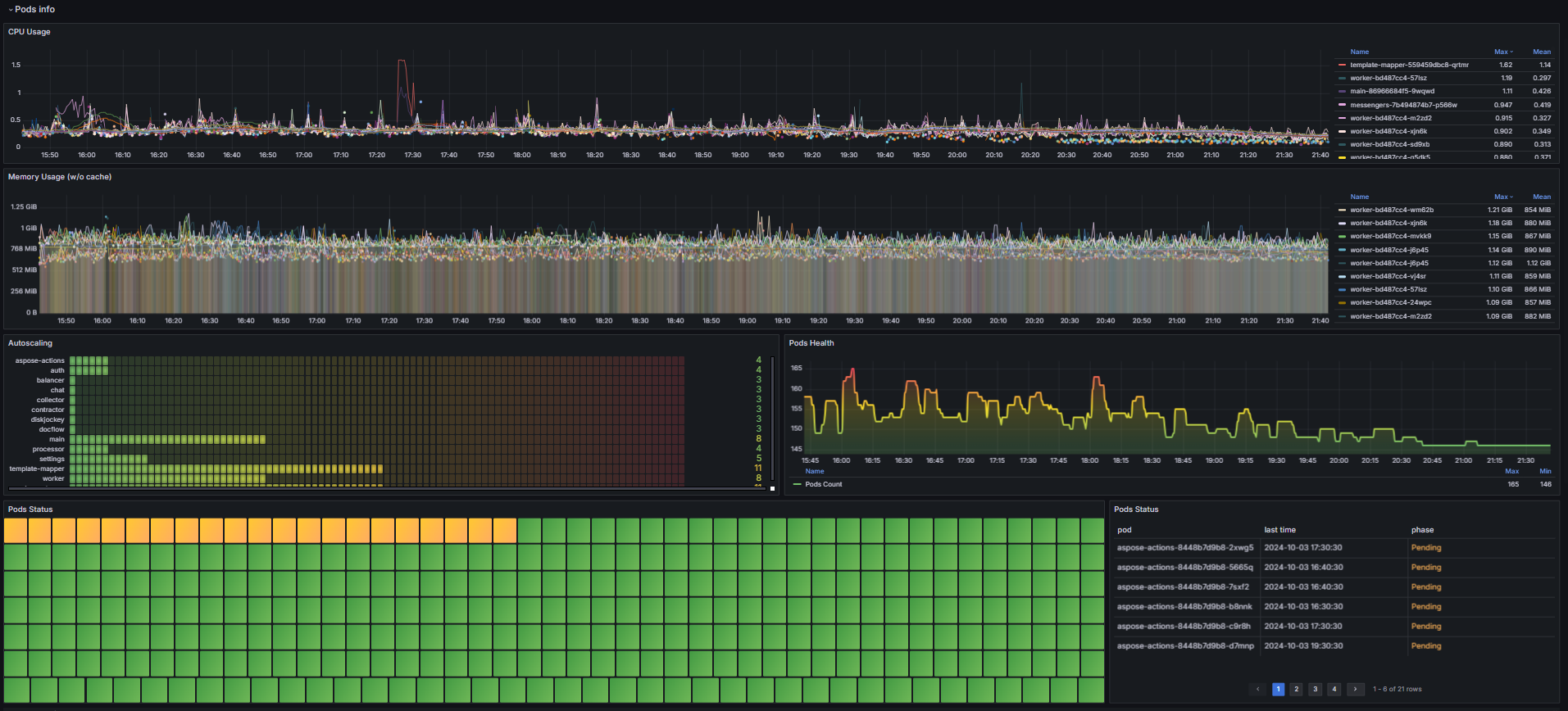
- CPU и Memory Usage — показывает, сколько CPU и ОЗУ ресурсов используется для работы подов. Объём потребления зависит от установленных лимитов;
- Pod Status — количество перезапусков подов за определённый период. Нормой являются нулевые или единичные перезапуски. Постоянно растущее число перезапусков одного пода указывает на проблему внутри контейнера, например, завершение его работы с ошибкой или неудачная проверка работоспособности (failed liveness probe);
- Autoscaling — число реплик сервисов. Резкий рост кривой графика может указывать на недостаток ресурсов или загруженность сервиса. В таком случае увеличьте объём ресурсов и количество реплик, а также лимиты для подов. Затем изучите логи сервисов, чтобы выявить возможные источники неполадок и устранить их.
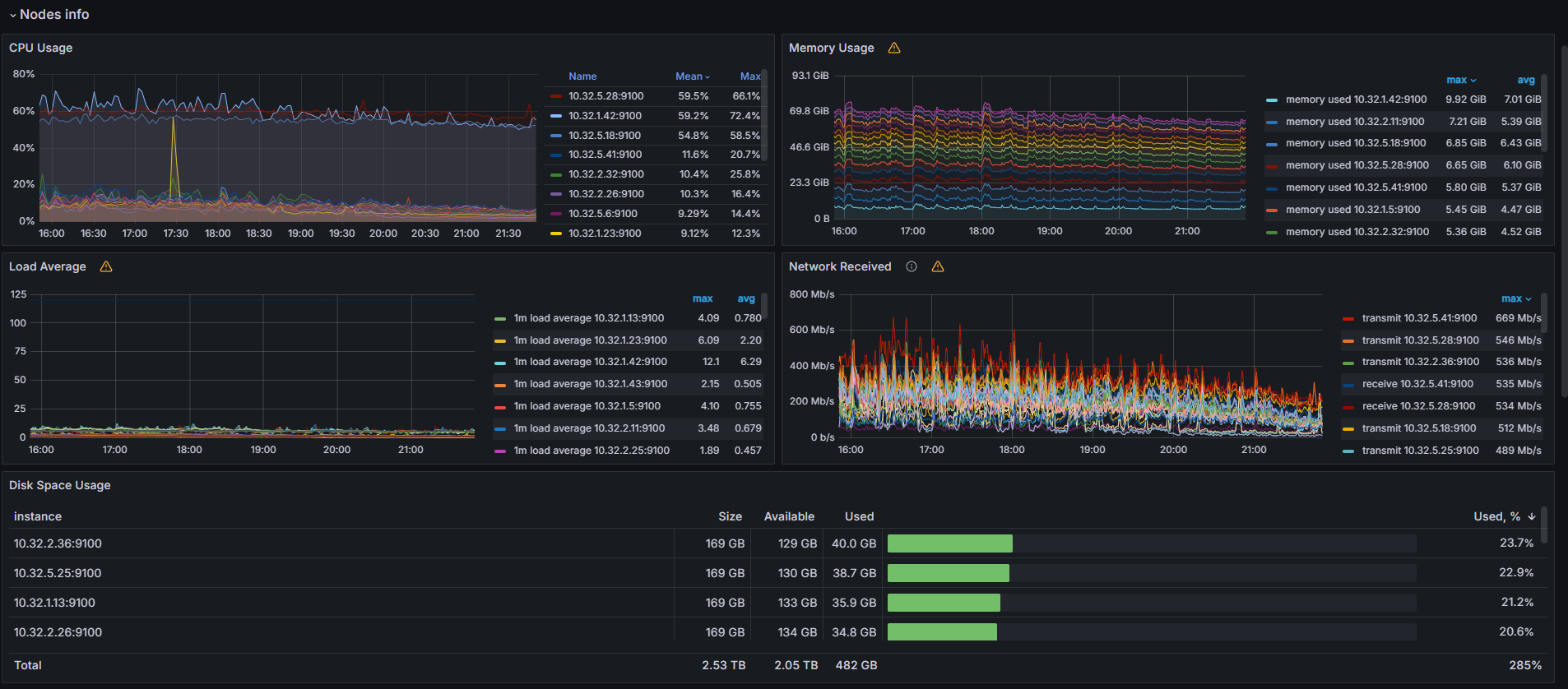
Раздел «Nodes info»
В этом разделе содержится информация о состоянии кластера, включая графики, отображающие потребление CPU и памяти, среднюю нагрузку, сетевой трафик и доступное дисковое пространство на нодах. На основе этих данных можно выявить нештатные ситуации и принять меры для их устранения.
При устойчивой высокой нагрузке (заполнение CPU больше 70%, использование памяти больше 80%) добавьте дополнительные ноды (8CPU, 16Mem). Рекомендуемая конфигурация — от 8 CPU, 16 ГБ RAM.
Если вы развернули стандартный кластер Kubernetes, установите систему Linux для работы в условиях высокой нагрузки, чтобы обеспечить оптимальную производительность кластера.
В следующих разделах представлена информация о мониторинге состояния баз данных: Postgres, RabbitMQ, MongoDB, Redis или Valkey.
Раздел «Postgres»
Наиболее важным графиком в этом разделе является Stat activity. Он показывает информацию по текущей активности. Если значение графика приближается к 80‑90% от максимального (Max Connections), увеличьте параметр max_connections и проанализируйте пулы соединений в приложениях.
В блоке DB Size вы можете отслеживать, сколько свободного места доступно в хранилище. Нормой считается заполнение диска не более чем до 85%. Критичным значением является 90%. Для корректной работы базы данных очистите её от ненужных и устаревших записей или увеличьте размер хранилища.
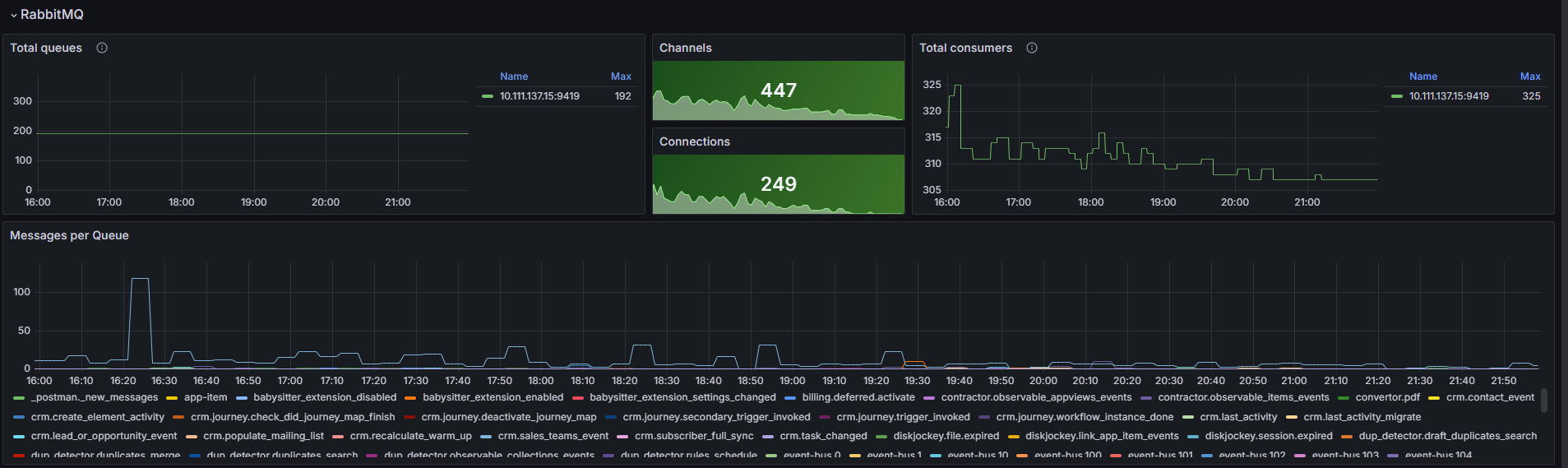
 Раздел «RabbitMQ»
Раздел «RabbitMQ»
Обратите внимание на график Messages per Queue. Он показывает сообщения в очереди. С его помощью можно определить, в каком микросервисе накапливаются сообщения. Если количество сообщений монотонно растёт или не уменьшается, перезагрузите соответствующий микросервис и изучите логи сервиса с помощью Loki.
Раздел «MongoDB»
В этом разделе вы можете наблюдать за показателями открытых подключений, нагрузкой на память и операциями запросов.

На графике Query Operations отображается, сколько операций в секунду выполняется в базе данных MongoDB. Эти метрики позволяют отслеживать производительность и эффективность хранилища. В норме скорость отклика на поступающие запросы должна оставаться стабильной. Если уровень нагрузки не меняется, а время выполнения запросов увеличивается, оптимизируйте запросы или добавьте индексы в БД.
В блоке Connection Count можно посмотреть количество активных подключений к базе данных. Сравните текущее число соединений с максимальным значением, которое задаётся в параметре max_connections. Если вы видите, что кривая графика приближается к установленному лимиту:
- Измените значение параметра max_connections на более высокое.
- Проанализируйте сервисы, которые подключаются к базе данных. Убедитесь, что не создаётся избыточных соединений и вовремя закрываются неиспользуемые.
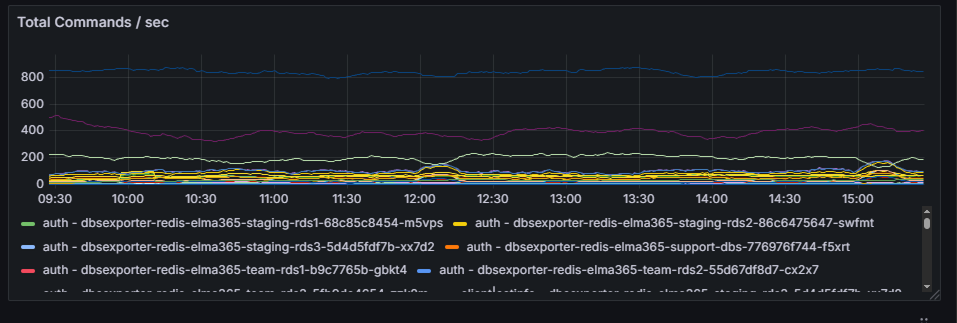
Раздел «Cache»
В этом разделе можно отследить производительность сервера кеширования данных. Отображаются метрики той службы, которая используется в вашей конфигурации: Valkey или Redis. На графиках вы увидите:
- CPU, Memory — объём потребления памяти. Приближение к значению maxmemory приводит к вытеснению ключей — автоматическому удалению части данных для высвобождения ресурсов.
При разовом достижении максимального объёма перезапустите ваш сервер кеширования данных. Если это не помогает и потребление памяти остаётся близким к максимальному, увеличьте объём памяти.
При высоком потреблении ресурсов проанализируйте также пользовательский код на предмет некорректного кеширования. Убедитесь, что кеш не содержит объёмных JSON‑файлов.
- Total Commands / sec — отображает общее количество команд в секунду, которые обрабатываются в Redis или Valkey. График служит для мониторинга производительности и эффективности кеша. Также позволяет анализировать различные метрики, связанные с исполнением команд в Redis или Valkey.
Раздел «Ingress»
В этом разделе вы можете узнать:
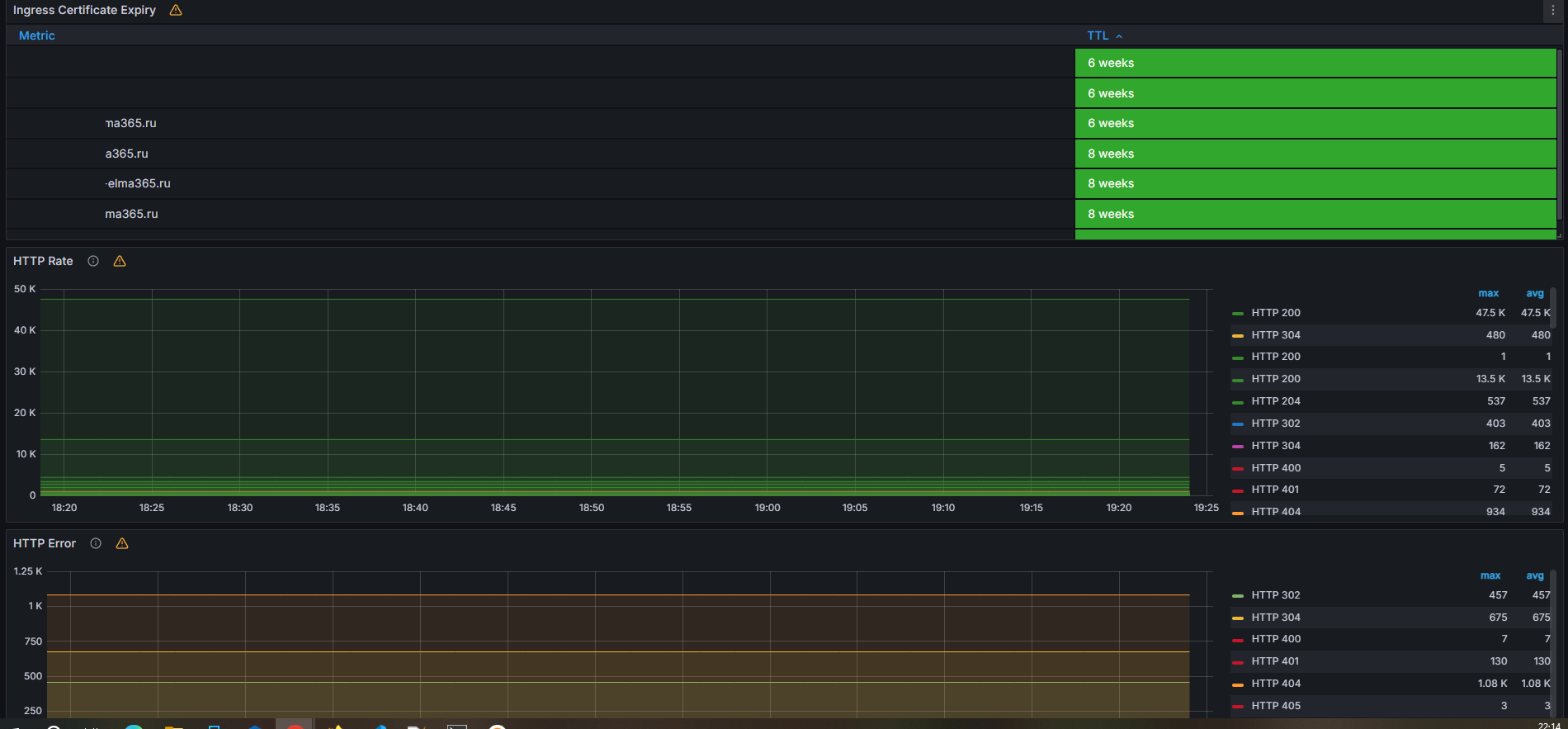
- Ingress Certificate Expiry — оставшийся срок действия сертификатов. Критичным является значение меньше 10 дней;
- HTTP Rate — количество HTTP‑запросов, проходящих через Ingress;
- HTTP Error — если на этом графике увеличилось количество ошибок, изучите логи Ingress Nginx для выявления причин.
Раздел «Logs»
Этот раздел служит для быстрого анализа логов. Вы можете выявить сервис с наибольшим количеством ошибок за указанный период и изучить логи, которые в нём зарегистрированы с помощью Loki.

Раздел «Linkerd»
Если установлен сервис Linkerd, в этом разделе можно отслеживать состояние mesh-соединений определённого deployment. Важно следить за графиком SUCCESS RATE. На нём отображается количество успешных запросов между сервисами. При возникновении проблем число таких подключений будет снижаться. Для большинства сервисов нормой является значение близкое к 100%. Обращайте внимание на падение количества успешных запросов ниже 95% — для ключевых сервисов или ниже 80% — для любого сервиса. В этом случае проанализируйте работу Linkerd, включая проверку внутреннего сертификата и анализ логов сервиса.
На представленном графике зафиксирован момент снижения производительности. При этом возникло предупреждение: level=warning msg="unable to parse quantity's suffix (config.linkerd.io/proxy-memory-limit)". В этом случае проверьте конфигурационный файл Linkerd и исправьте ошибки в параметрах requests и limits.

Раздел «Kubernetes Events – Stats»
С помощью графиков в этом разделе можно отслеживать различные события в кластере и получать информацию о состоянии подов.
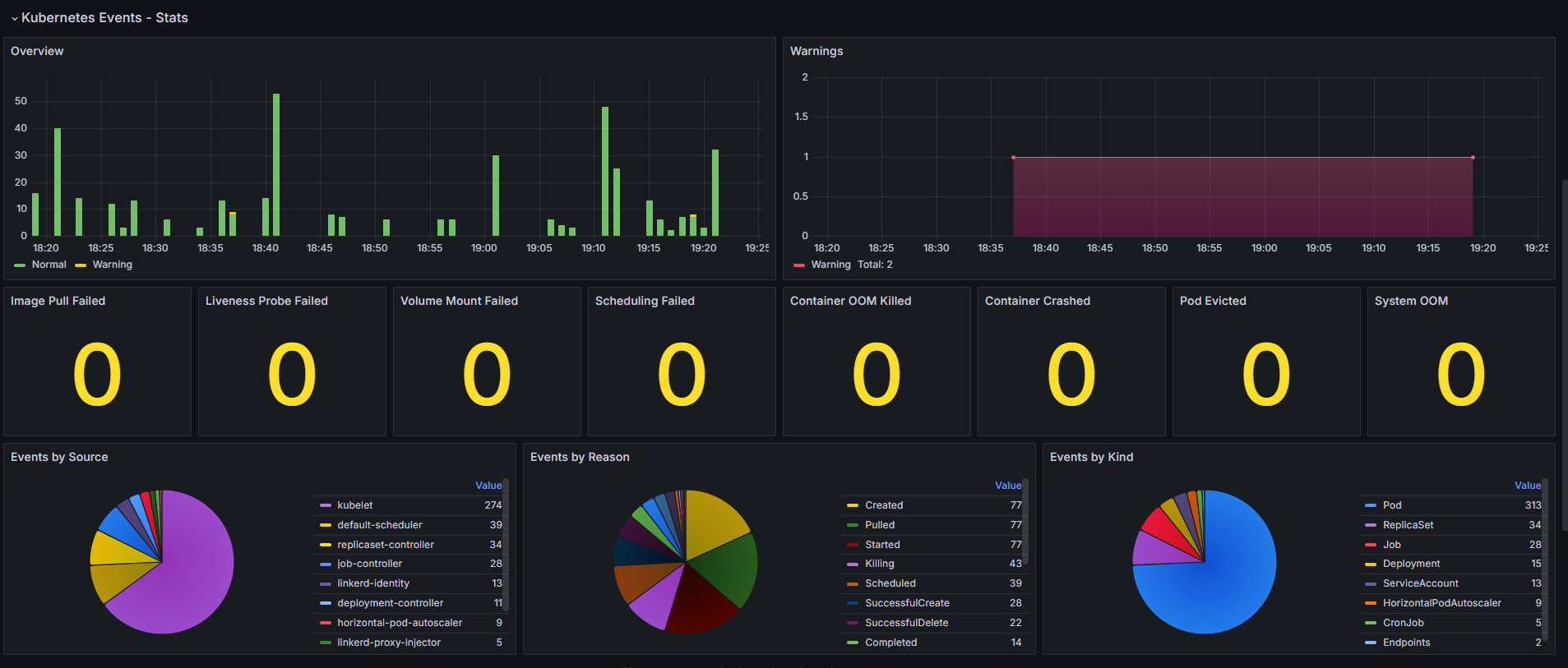
События, связанные с подами (Containers):
- Image Pull Failed — невозможно скачать образ контейнера для запуска пода, например, если недоступен контейнерный регистр или отсутствует запрашиваемый образ;
- Liveness Probe Failed — это событие появляется, если нарушена связь между подом и liveness probe, с помощью которого проверяется корректность работы пода;
- Volume Mount Failed — не удаётся смонтировать постоянный том (volume) или ресурс хранения. Такое поведение может возникнуть, если неправильно настроено хранилище либо есть проблемы с сетью или разрешениями;
- Container OOM Killed — под завершил работу из-за нехватки памяти. Событие появляется, если под потребляет слишком много памяти и узел не может обеспечить требуемые ресурсы;
- Container Crashed — аварийная остановка контейнера. Причиной может быть ошибка внутри контейнера или его некорректная работа;
- Pod Evicted — под удалён из-за нехватки памяти или CPU. Событие появляется, если перегружается узел или под потребляет большое количество ресурсов.
События, связанные с планированием (Scheduling):
- Scheduling Failed — это событие происходит, когда планировщик Kubernetes не может разместить под на узле из-за нехватки ресурсов или других ограничений.
События, связанные с системой (System):
- System OOM — это событие фиксируется, когда не хватает памяти на системном уровне, например из-за высокой нагрузки на узел или недостаточных системных ресурсов.