Горизонтальное автомасштабирование подов (HPA) — ключевой механизм обеспечения отказоустойчивости и экономии ресурсов в Kubernetes. Чтобы оптимально настроить HPA, регулярно анализируйте данные его мониторинга. Это позволит избежать перерасхода ресурсов и ухудшения производительности кластера под нагрузкой.
В этой статье рассмотрим:
- как читать данные в графиках HPA и таблице потребления ресурсов;
- как настроить оптимальные значения гарантированных ресурсов и лимитов для контейнеров;
- как выявить и уменьшить излишнюю нагрузку от сервисной сети (Linkerd, Istio).
Предварительные настройки для использования дэшборда HPA
Для корректной работы дэшборда HPA:
- Включите автомасштабирование сервисов в ELMA365.
- Установите:
- Prometheus и Grafana — для хранения и отображения данных. Подробнее читайте в статье «Установка средств мониторинга»;
- Loki — для сбора и хранения логов о работе системы;
- Linkerd или Istio — с помощью которых настраивается обработка связей между сервисами и отслеживаются параметры соединения.
После этого данные для дэшборда будут аккумулироваться в хранилище Prometheus и визуализироваться с помощью сервиса Grafana.
Настройка параметров на основе анализа HPA
Чтобы обеспечить оптимальное распределение ресурсов в кластере, регулярно анализируйте метрики их потребления и вносите необходимые корректировки в настройки горизонтального автомасштабирования подов (HPA). Рассмотрим основные этапы такого мониторинга.
Шаг 1. Анализ основных метрик потребления ресурсов
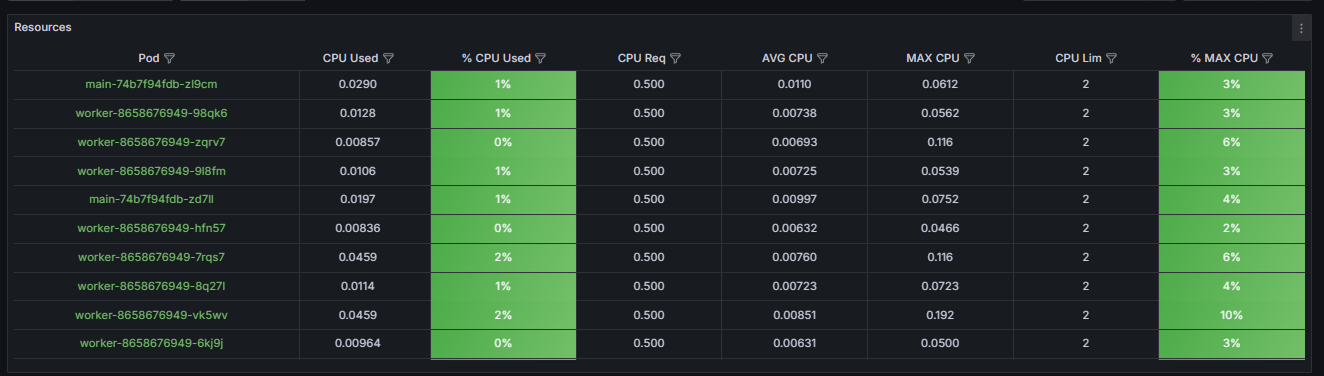
Таблица Resources отображает текущее состояние ресурсов по сервисам приложения ELMA365. Для каждого сервиса:
- Настройте параметры использования процессора (CPU). Для этого:
- Сравните максимальное потребление CPU (Max) и процент использования лимита (% Max).
- Если % Max превышает 80%, в файле values-elma365.yaml в блоке настроек нужного сервиса увеличьте лимит.
- Если % Max ниже 50%, уменьшите лимит для экономии ресурсов.
- Установите гарантированное потребление ресурсов (Req) на уровне между средним и максимальным значениями.
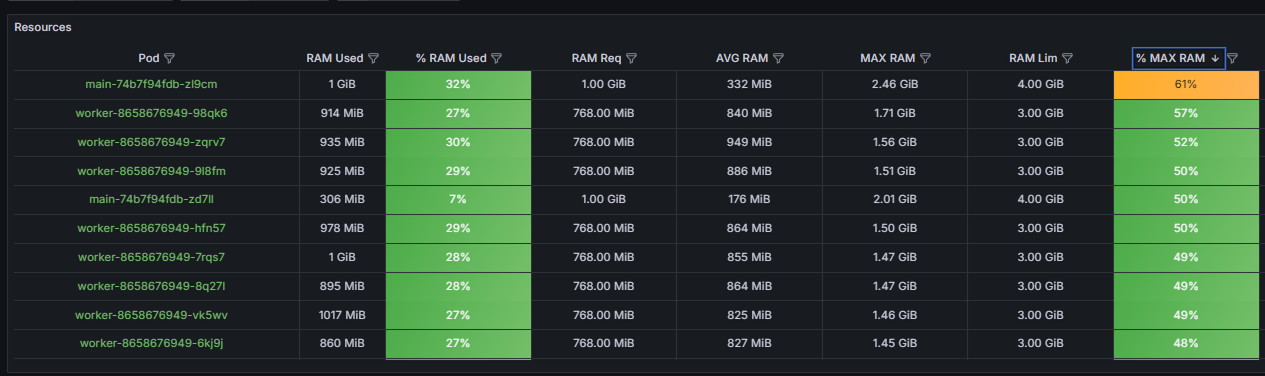
- Настройте параметры оперативной памяти (RAM). Для этого:
- Убедитесь, что процент использования лимита % Max не превышает 80%.
- Если превышает это значение, увеличьте лимит (Lim).
- Установите гарантированное потребление ресурсов (memory.req) на 10‑15% выше максимального потребления (Max).
Подробнее о работе с данными в таблице Resources читайте в разделе «Анализ текущего состояния ресурсов и настройка параметров».
Шаг 2. Анализ состояния автомасштабирования
Изучите график Autoscaling, чтобы отследить динамику реплик по сервисам. Подробнее читайте в разделе «Анализ поведения HPA».
Шаг 3. Оптимизация нагрузки от сервисной сети (service mesh)
Проанализируйте:
- Графики Mesh CPU Usafe и Mesh Memory Usage.
- Потребление ресурсов по каждому сервису приложения ELMA365 в детальных блоках.
При выявлении высокой нагрузки от сервисной сети (Linkerd или Istio) в файле values-elma365.yaml добавьте аннотации, чтобы ограничить ресурсы вспомогательных контейнеров (sidecar):
- для Istio:
sidecar.istio.io/proxyCPU: "100m"
sidecar.istio.io/proxyMemory: "128Mi"
sidecar.istio.io/proxyCPULimit: "500m"
sidecar.istio.io/proxyMemoryLimit: "512Mi"
- для Linkerd:
config.linkerd.io/proxy-cpu-limit: "0.5"
config.linkerd.io/proxy-cpu-request: "0.1"
config.linkerd.io/proxy-memory-limit: 128Mi
config.linkerd.io/proxy-memory-request: 64Mi
Шаг 4. Пересчёт целевых значений HPA
После изменения гарантированных ресурсов (Req), лимитов и параметров сервисной сети (Linkerd или Istio) пересчитайте целевые значения HPA. Чтобы обеспечить оптимальную и эффективную работу кластера, регулярно выполняйте цикл «Анализ дэшборда HPA → Настройка параметров потребления ресурсов → Повторный анализ HPA».
Анализ текущего состояния ресурсов и настройка параметров
В таблице Resources отображаются ключевые метрики ресурсов, которые используются подами:
- показатели использования процессора (CPU);
- показатели потребляемой оперативной памяти (RAM).
Рассмотрим подробнее, как читать данные в таблице:
- Used.
Указывает, сколько ресурсов потребляется подами deployment в текущий момент: оперативной памяти (RAM) и процессора (CPU). Чтобы оценить корректность текущих настроек, сравните значение Used с параметрами гарантированных ресурсов (Req) и лимитов (Lim). Если значение Used приближается к значению в колонке Lim — это значит, что ресурсы, выделенные для подов, достигли установленного лимита. В файле values‑elma365.yaml увеличьте масштабирование подов или установите более высокое значение для параметра limits.
Отображает текущий процент использования установленного лимита ресурсов, который отображается в колонке Lim:
- % CPU Used — допустимый уровень нагрузки до 80%. Если этот порог регулярно превышается, механизм HPA должен автоматически увеличить количество экземпляров подов. Если автомасштабирование не происходит, проверьте настройки HPA: максимальное число экземпляров и скорость масштабирования.
Важно: значение % CPU Used больше 95% создаёт риск замедления работы пода (троттлинга CPU). В этом случае увеличьте лимит памяти для пода или ожидайте автомасштабирования, если оно корректно настроено, но ещё не успело среагировать на достижение лимита; - % RAM Used — если значение этого параметра:
- выше 60% — ячейка в таблице отмечается жёлтым цветом. Отслеживайте состояние пода;
- выше 80% — ячейка в таблице отмечается красным цветом. Требуются срочные корректировки установленных настроек выделения ресурсов.
Высокий процент использования памяти увеличивает риск принудительного завершения работы пода из-за исчерпания доступных ресурсов (OOMKilled). Ситуация, когда значение % Ram Used — высокое, а % CPU Used — низкое, указывает на утечку памяти или на слишком жёсткие лимиты. Скорректируйте их в файле values-elma365.yaml, увеличив значение параметра limits для нужного сервиса.
Отображает гарантированные ресурсы, которые резервируются в кластере для deployment. Оптимальное значение этого параметра должно находится в диапазоне между средним (AVG) и максимальным (MAX) потреблением ресурсов:
- для процессора (CPU) — установите значение Req в диапазоне p75‑p90 от максимального потребления за 24 часа. Например, при максимальном потреблении MAX CPU = 500m и среднем — AVG = 100m рекомендуется установить Req: 300m. Такой подход обеспечит наличие ресурсов для стандартных пиковых нагрузок, но не приведёт к избыточному резервированию;
- для оперативной памяти (RAM) — установите значение Req близко к максимальному с резервом в 10‑15%. Например, при максимальном потреблении памяти в 1GiB, установите memory.req: 1100Mi. Это предотвратит принудительное завершение работы пода (eviction) в периоды ожидаемых пиков использования памяти.
- AVG.
Отображает среднее потребление ресурсов за 24 часа. Позволяет анализировать базовую нагрузку. Применяется, чтобы оценить стоимость эксплуатации и запланировать наличие необходимых ресурсов. Если установленное гарантирование значение (Req) многократно превышает среднее потребление (AVG) — в 3‑5 раз, это может указывать на излишнее резервирование ресурсов и неэффективные затраты.
Отображает максимальное потребление ресурсов за 24 часа. Эта метрика является ключевой для корректной настройки лимитов (limits) и оценки пиковой нагрузки:
- для использования процессора (CPU) — лимит должен превышать максимальное потребление (MAX). Рекомендуется использовать коэффициент 1.2‑1.5. Например, при максимальном потреблении MAX CPU = 800m, установите cpu.lim: 1000m. Это обеспечит запас ресурсов для обработки непредвиденных пиков нагрузки;
- для оперативной памяти (RAM) — лимит устанавливается незначительно выше максимального потребления (MAX), достаточно 10‑20%. Цель — предотвратить исчерпание всей доступной памяти ноды в случае ошибки. Например, при максимальном потреблении памяти 1.2GiB, установите memory.lim: 1400Mi.
Определяет жёсткое ограничение для максимального потребления ресурсов подами. Настраивайте этот параметр после анализа метрик MAX и % Used. Систематически высокое значение в столбце % Max указывает на то, что установленный лимит слишком жёсткий. Это может ограничить производительность пода.
- % Max.
Отображает процентное соотношение максимального потребления ресурсов за 24 часа по отношению к установленному лимиту (колонка Lim). Этот показатель служит основным индикатором корректности настроенных лимитов для подов.
Рекомендуемые значения:
- для процессора (CPU) — в диапазоне 70‑90%. Такой показатель указывает на то, что при пиковой нагрузке использование ресурсов может приблизиться к лимиту. Однако это не вызовет ограничений производительности пода (троттлинга CPU);
- для оперативной памяти (RAM) — менее 85%.
Требуется скорректировать лимиты потребления ресурсов:
- для процессора (CPU):
- если значение % Max превышает 95%, лимит установлен недостаточно высоким. Увеличьте его;
- если значение % Max меньше 50%, лимит — избыточный, и его можно уменьшить для более эффективного распределения нагрузки на узлах кластера;
- для оперативной памяти (RAM) — если значение % Max превышает 90%, это свидетельствует о критической нехватке ресурсов. Увеличьте лимит.
Анализ поведения HPA
На графике Autoscaling вы можете увидеть, как меняется число работающих реплик по сервисам.
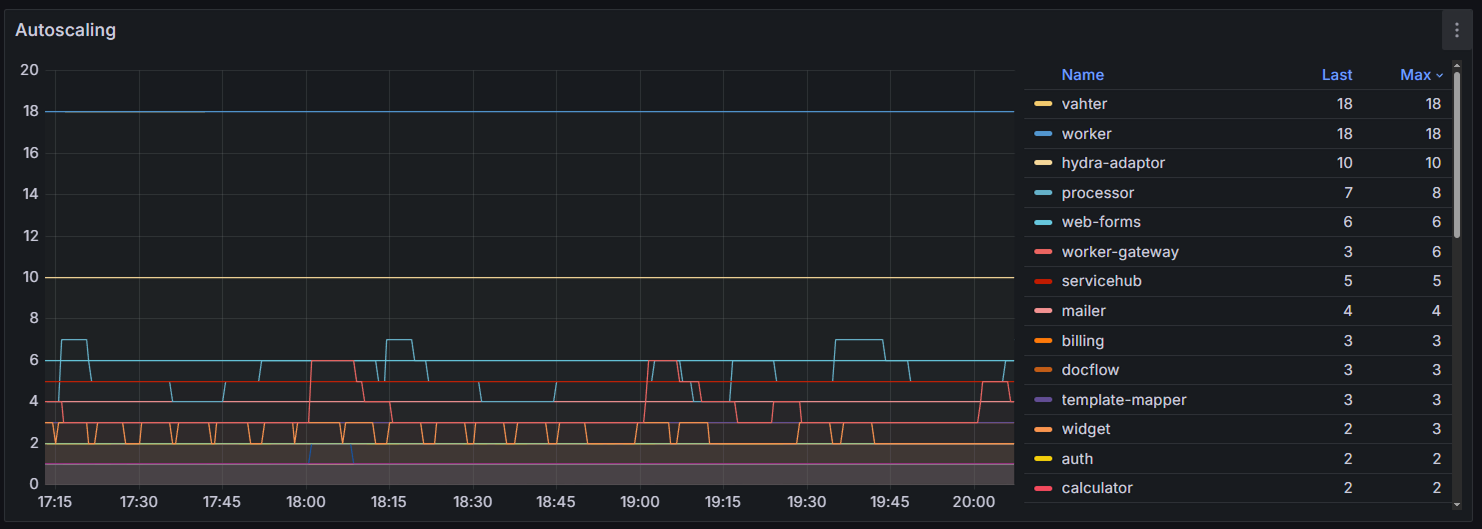
Обращайте внимание на:
- резкие и частые колебания количества подов — указывают на избыточную чувствительность настройки HPA;
- постепенный ступенчатый рост числа подов с последующим резким снижением — указывает на дневную нагрузку. Убедитесь, что механизм HPA успевает добавлять реплики сервиса до наступления пиковой нагрузки;
- прямая линия на уровне параметра maxReplicas — достигнут установленный предел автомасштабирования. Если при этом в таблице Resources фиксируется стабильно высокое значение % Used, в файле values‑elma365.yaml увеличьте значение параметра maxReplicas или оптимизируйте приложение, повысив значение limits для нужного сервиса.
Потребление ресурсов вспомогательными инструментами
На графиках Mesh CPU Usage и Mesh Memory Usage вы можете оценить по каждому сервису потребление ресурсов только вспомогательными контейнерами (sidecar) дополнения Linkerd (linkerd‑proxy) или Istio (istio‑proxy). Выбор используемой сервисной сети вы определяете при настройке инфраструктуры.
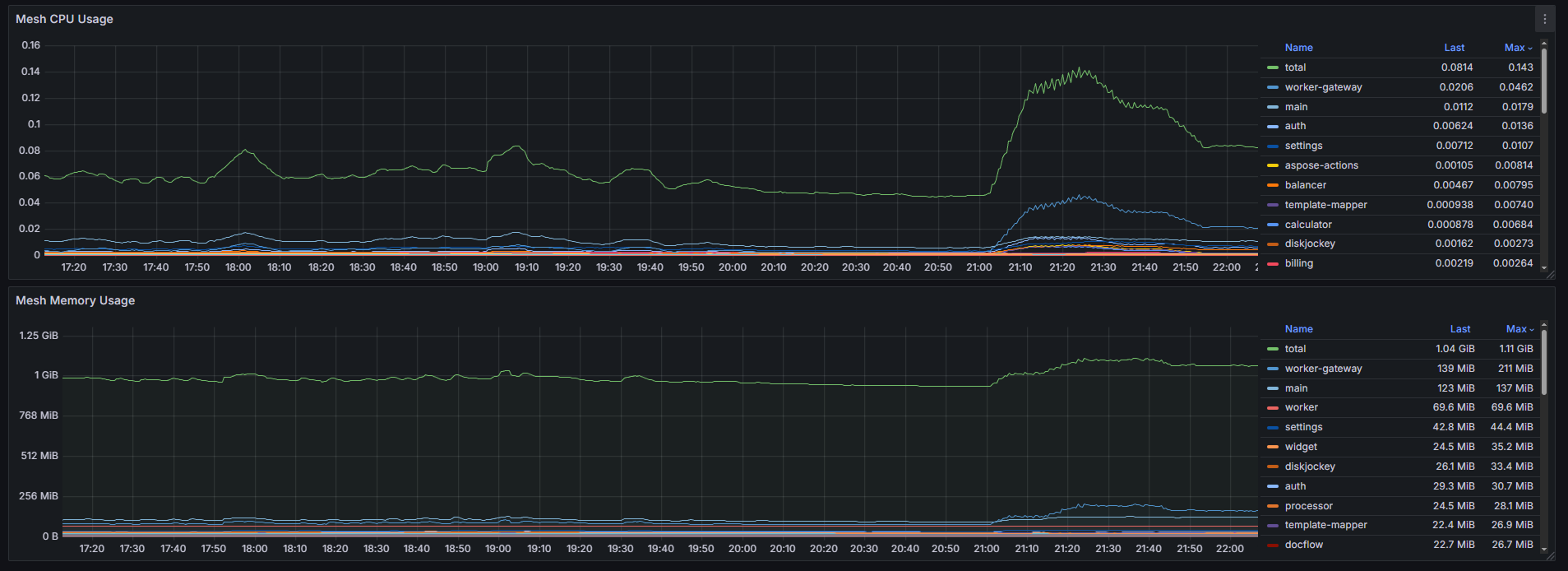
При анализе потребления ресурсов вспомогательными контейнерами:
- Сравните Mesh CPU Usage с общим CPU Usage кластера. Если доля ресурсов CPU, которая используется вспомогательными контейнерами, превышает 10‑15% от общего потребления кластера, это указывает на значительные дополнительные затраты ресурсов.
- Сравните Mesh Memory Usage с Memory Usage сервисов. Если память, потребляемая вспомогательными контейнерами, составляет 30‑50% и более от памяти сервисов, требуется оптимизация.
- Выявите поды с высокой нагрузкой вспомогательных контейнеров. По графику можно определить, в какие периоды или на каких сервисах нагрузка на Linkerd или Istio возрастает, например, при массовой рассылке событий.
Оптимизировать потребление ресурсов сервисной сетью (Linkerd, Istio) можно с помощью аннотаций в файле values‑elma365.yaml.
Анализ потребления ресурсов по каждому сервису
В дэшборде HPA вы также можете посмотреть детальные блоки с данными о потребляемых ресурсах для каждого сервиса, например main:
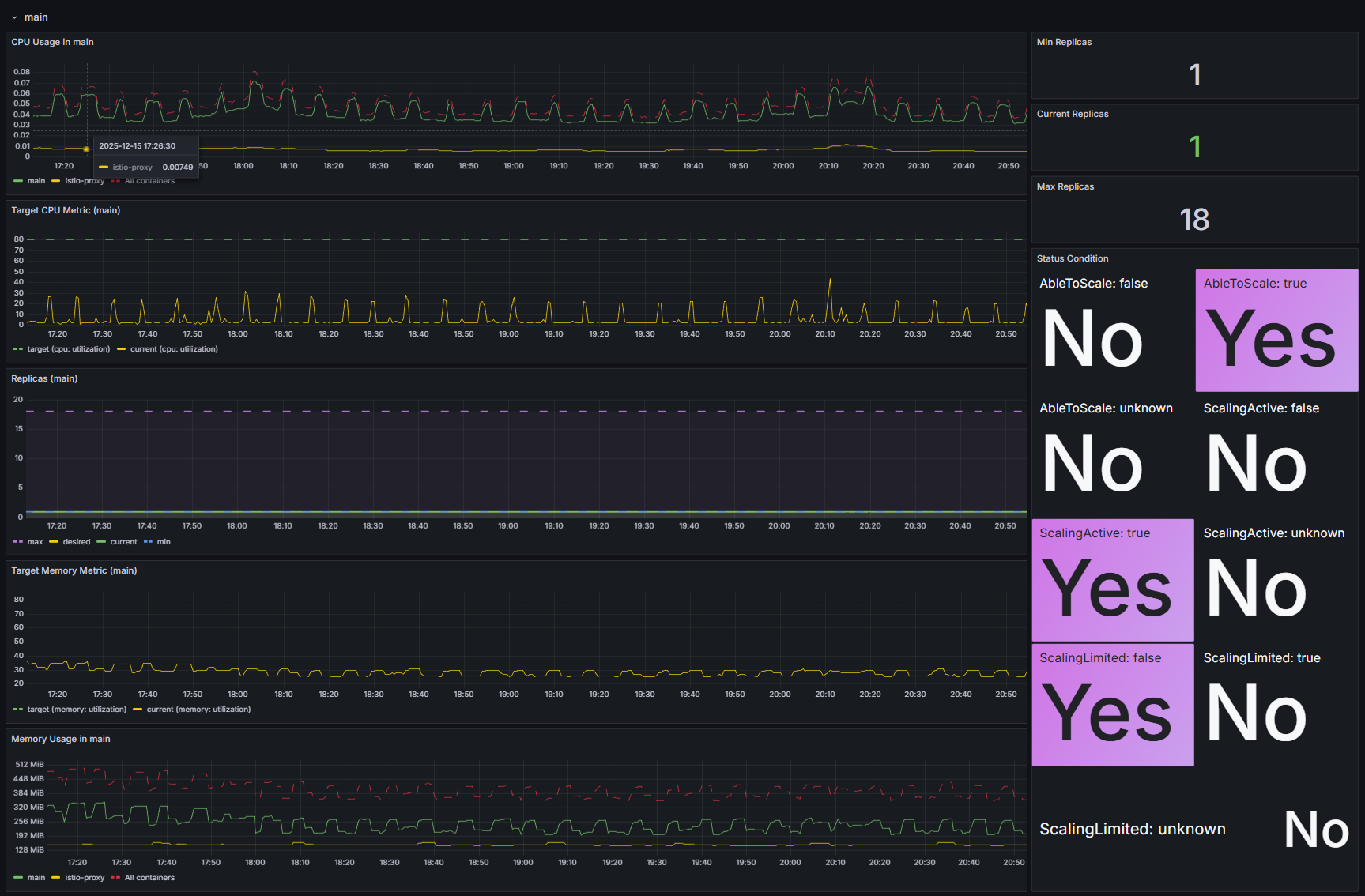
Проанализируйте эти данные, чтобы задать оптимальные настройки автомасштабирования подов для определённого сервиса. Рассмотрим, на что обращать внимание в графиках:
- CPU Usage — отображает потребление CPU основными контейнерами сервиса и вспомогательными контейнерами (sidecar) Istio или Linkerd. Если потребление вспомогательным контейнером сопоставимо с потреблением основного контейнера или превышает его, оптимизируйте конфигурацию Istio или Linkerd;
- Target CPU Metric — определяет целевой процент использования гарантированных ресурсов (Req), к которому стремится HPA. Регулируя этот параметр, вы можете управлять интенсивностью процесса автомасштабирования;
- Replicas (Min/Max/Current) — отображает текущий статус реплик. Если при стабильной нагрузке текущее (Current) количество реплик находится продолжительное время в максимальном значении (Max), рекомендуется:
- в файле values‑elma365.yaml увеличить значение параметра maxReplicas;
- оптимизировать потребление ресурсов;
- Target Memory Metric — отображает целевое и текущее потребление памяти.
Важно: управление автомасштабированием по параметру потребляемой памяти часто приводит к нестабильности системы. Применяйте такой подход с осторожностью; - Memory Usage — отображает потребление оперативной памяти основными контейнерами сервиса и вспомогательными контейнерами (sidecar) Istio или Linkerd. Если вспомогательные контейнеры используют слишком много ресурсов, установите для них ограничения. Для этого в файле values‑elma365.yaml добавьте аннотации в блоке настроек нужного сервиса.