Шардирование
Шардирование (или шардинг, от англ. sharding) — это метод горизонтального масштабирования базы данных, при котором большая таблица разбивается на более мелкие части (шарды) и распределяется по разным серверам. Это позволяет обойти технические ограничения одного сервера, увеличить производительность и надёжность системы.
В отличие от партиционирования, которое работает внутри одной СУБД, шардирование распределяет данные по нескольким узлам кластера.
В этом руководстве мы разберём виды шардирования (горизонтальное, вертикальное, доменное, динамическое, виртуальное, консистентное), отличия от репликации и партиционирования, как выбрать ключ шардирования, а также покажем примеры кода и обсудим сложности распределённых транзакций. Материал обновлён в 2026 году и ориентирован на практикующих разработчиков и архитекторов.
📖 Содержание
- Что такое шардирование БД
- Шардирование простыми словами
- Зачем нужно шардирование
- Когда использовать шардирование
- Как работает шардирование
- Что такое ключ шардирования
- Пример шардирования базы данных
- Виды шардирования
- Горизонтальное и вертикальное шардирование
- Что такое виртуальное шардирование
- Что такое динамическое шардирование
- Что такое доменное шардирование
- Что такое консистентное шардирование
- Шардирование и партиционирование: в чем разница
- Шардирование и репликация: в чем разница
- Сложности шардирования: распределённые транзакции и JOIN
- Преимущества и недостатки
- Как сделать шардирование (пошагово, миграция, решардинг)
- Инструменты и реальные кейсы
- FAQ
- Заключение
Что такое шардирование базы данных
Шардирование — это разделение данных на несколько независимых частей (шардов), которые размещаются на разных серверах. Каждый шард содержит только часть общего набора данных и обслуживает собственные запросы.
| Термин | Определение |
|---|---|
| Шард | Отдельная часть данных, хранящаяся на одном узле |
| Шардирование (шардинг) | Процесс разделения данных между серверами |
| Узел (node) | Сервер хранения данных в кластере |
| Кластер | Группа взаимосвязанных серверов |
| Распределенная база данных | БД, работающая на нескольких узлах |
Шардирование простыми словами
Шардирование можно сравнить с библиотекой, в которой книги распределены по нескольким зданиям. Вместо хранения всех книг в одном месте каждая категория размещается отдельно. Благодаря этому посетители быстрее находят нужную информацию, а нагрузка распределяется между несколькими зданиями.
По такому же принципу работают высоконагруженные базы данных: данные распределяются между несколькими серверами, что ускоряет обработку запросов и повышает производительность системы.
Зачем нужно шардирование
Шардирование применяется для горизонтального масштабирования, повышения производительности и отказоустойчивости при росте объёма данных и нагрузки.
| Проблема | Как помогает шардирование |
|---|---|
| Большой объем данных | Данные распределяются между серверами, каждый хранит только часть |
| Высокая нагрузка | Запросы распределяются по узлам, снижая нагрузку на каждый |
| Ограничения одного сервера | Горизонтальное масштабирование — добавление новых узлов |
| Медленная работа БД | Ускоряется обработка запросов за счёт параллельных операций |
| Рост пользователей | Система остаётся отзывчивой при увеличении числа клиентов |
Шардирование особенно актуально для высоконагруженных систем, где количество записей может исчисляться миллионами или миллиардами.
Когда использовать шардирование
Шардирование рекомендуется использовать в случаях, когда объем данных или нагрузка на базу данных постоянно растут и возможности одного сервера становятся ограничением для дальнейшего масштабирования.
| Ситуация | Нужно шардирование |
|---|---|
| Миллионы записей в БД | ✅ Да |
| Высокая нагрузка на сервер (CPU, I/O) | ✅ Да |
| Большое количество одновременных пользователей | ✅ Да |
| Небольшая локальная база данных | ❌ Нет |
| Стартап с несколькими тысячами записей | ❌ Обычно нет |
| Корпоративная система с быстрым ростом данных | ✅ Да |
Важно понимать, что шардирование увеличивает сложность архитектуры. Поэтому для небольших проектов обычно достаточно оптимизации запросов, индексов или репликации.
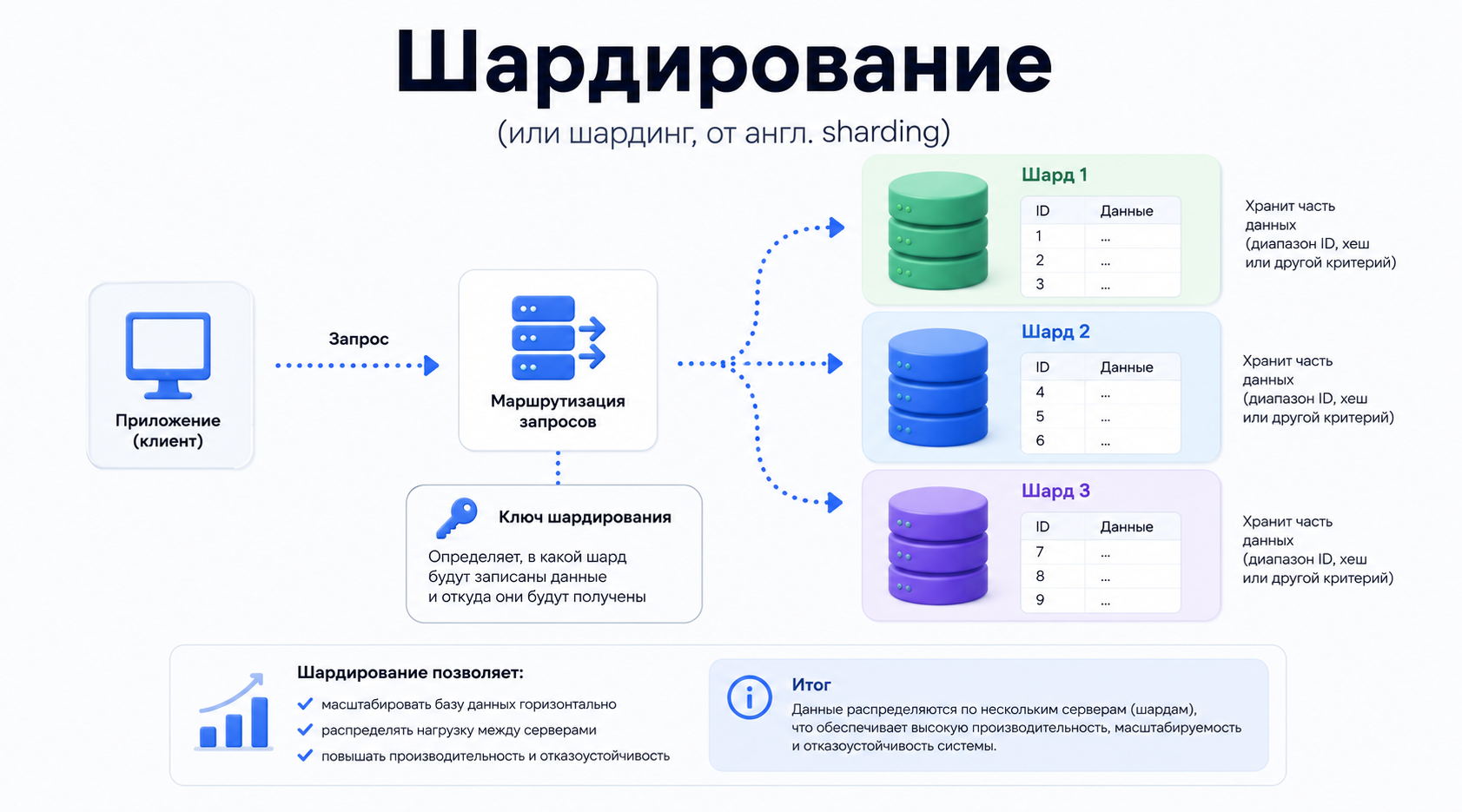
Как работает шардирование
Шардирование работает на основе правил распределения данных между узлами кластера. Система по запросу определяет нужный шард на основе ключа и направляет запрос на соответствующий сервер.
Основная схема выглядит следующим образом:
Пользователь отправляет запрос.
Система вычисляет хеш от ключа шардирования (например, user_id).
Номер шарда = хеш % количество_шардов.
Запрос направляется на соответствующий сервер.
Сервер обрабатывает данные и возвращает результат.
| Этап | Что происходит |
|---|---|
| Получение запроса | Система принимает обращение |
| Определение шарда | Вычисляется место хранения данных |
| Маршрутизация | Запрос направляется на нужный узел |
| Выполнение | Сервер обрабатывает запрос |
| Ответ | Результат возвращается клиенту |
Что такое ключ шардирования
Ключ шардирования (Shard Key) — это поле или набор полей, по которым система определяет, в каком шарде будут храниться данные. От правильного выбора ключа зависит равномерность распределения нагрузки между серверами и эффективность масштабирования базы данных.
Например, в качестве ключа шардирования могут использоваться идентификатор пользователя, номер заказа, регион или результат хеширования.
")
| Тип данных | Возможный ключ шардирования |
|---|---|
| Пользователи | ID пользователя |
| Заказы | ID заказа |
| Клиенты | Регион |
| Интернет-магазин | ID клиента |
| Логи событий | Дата или диапазон времени |
Неправильно выбранный ключ может привести к неравномерному распределению данных и перегрузке отдельных узлов кластера.
Пример шардирования базы данных
Рассмотрим простой пример шардирования БД по идентификатору пользователя.
Предположим, база данных содержит 30 миллионов пользователей. Вместо хранения всей информации на одном сервере данные распределяются между несколькими шардами.
| Диапазон ID пользователей | Шард |
|---|---|
| 1–10 млн | Сервер 1 |
| 10–20 млн | Сервер 2 |
| 20–30 млн | Сервер 3 |
Когда пользователь с ID 15 000 000 выполняет запрос, система автоматически определяет нужный шард и направляет запрос на второй сервер.
Такой подход снижает нагрузку на отдельный узел и обеспечивает более высокую производительность распределенной базы данных.
Пример шардирования на Python:
def get_shard_id(key, num_shards):
return hash(key) % num_shards
user_id = 12345
shard = get_shard_id(user_id, 4)
# Запрос к базе на сервере шарда
print(f"Пользователь {user_id} направлен на шард {shard}") Такой подход прост в реализации, но требует осторожности при изменении количества шардов (см. раздел о решардинге).
Виды шардирования
Существует несколько способов организации шардирования данных. Основные виды: горизонтальное, вертикальное, доменное, динамическое, виртуальное и консистентное.

| Вид шардирования | Особенность | Пример использования |
|---|---|---|
| Горизонтальное | Деление строк таблицы по ключу | Пользователи с ID 1–10M на сервер A, 10M–20M на сервер B |
| Вертикальное | Деление столбцов и сущностей | Профили — на один сервер, заказы — на другой |
| Доменное | Деление по бизнес-областям | Пользователи, платежи, каталог — отдельные базы |
| Динамическое | Автоматическое перераспределение данных | Автомасштабирование в облачных средах |
| Виртуальное | Использование виртуальных шардов | Гибкое добавление узлов без изменения приложения |
| Консистентное | Распределение через хеширование | Redis Cluster, Cassandra, DynamoDB |
Горизонтальное и вертикальное шардирование
Горизонтальное шардирование считается наиболее распространенным вариантом для масштабирования распределенных баз данных.
| Параметр | Горизонтальное | Вертикальное |
|---|---|---|
| Что разделяется | Строки таблицы | Столбцы и сущности |
| Масштабируемость | Высокая | Средняя |
| Использование | Высоконагруженные БД | Разделение сервисов |
| Производительность | Высокая | Зависит от структуры данных |
При горизонтальном шардировании пользователи могут распределяться по диапазонам ID, регионам или результатам хеширования.
Что такое виртуальное шардирование
Виртуальное шардирование использует промежуточный слой между данными и физическими серверами.
Вместо привязки данных к конкретному серверу система сначала распределяет их по виртуальным шардам, а затем сопоставляет виртуальные шарды с физическими узлами.
| Преимущество | Результат |
|---|---|
| Гибкость масштабирования | Проще добавлять новые серверы |
| Балансировка нагрузки | Более равномерное распределение данных |
| Управляемость | Упрощение администрирования |
Что такое динамическое шардирование
Динамическое шардирование позволяет автоматически перераспределять данные при изменении нагрузки.
Система самостоятельно определяет необходимость добавления новых узлов и переносит данные между шардами.
| Возможность | Польза |
|---|---|
| Автоматическое распределение | Снижение ручного управления |
| Масштабирование в реальном времени | Поддержка роста нагрузки |
| Балансировка данных | Повышение производительности |
Что такое доменное шардирование
Доменное шардирование предполагает разделение данных по бизнес-сущностям.
Например:
пользователи;
заказы;
платежи;
товары;
обращения клиентов.
| Домен | Отдельный шард |
|---|---|
| Пользователи | User DB |
| Заказы | Order DB |
| Платежи | Payment DB |
| Каталог товаров | Product DB |
Такой подход часто используется в микросервисной архитектуре.
Что такое консистентное шардирование
Консистентное шардирование основано на алгоритмах консистентного хеширования.
Консистентное хеширование — это алгоритм распределения данных, при котором добавление или удаление узла вызывает перемещение только K/N данных (где N — число узлов), а не всех данных. Это критически важно для крупных кластеров, где решардинг всей базы был бы катастрофой.
Принцип: ключи и узлы хешируются в одно кольцо (от 0 до 2^32-1). Каждый ключ сопоставляется с первым узлом, идущим по часовой стрелке. При добавлении нового узла перемещаются только ключи, которые попадают в его диапазон. Это делает систему устойчивой к изменениям.
Пример псевдокода:
# Предположим, кольцо представлено отсортированным списком хешей узлов.
# Для ключа вычисляем хеш, ищем первый узел с хешем >= хеш(ключа).
def get_node(key, ring):
key_hash = hash(key)
for node_hash in sorted(ring):
if node_hash >= key_hash:
return node
return first_node # замыкание кольца Главная особенность заключается в том, что при добавлении или удалении сервера переносится только часть данных, а не весь массив.
| Без консистентного хеширования | С консистентным хешированием |
|---|---|
| Массовое перераспределение данных | Переносится небольшая часть данных |
| Высокая нагрузка при масштабировании | Более стабильная работа |
| Сложность добавления узлов | Простое расширение кластера |
Консистентное шардирование активно применяется в Redis Cluster, Apache Cassandra, Amazon DynamoDB, а также распределённые кеши (Memcached).
Шардирование и партиционирование: в чем разница
Шардирование и партиционирование часто путают, однако это разные технологии. Партиционирование — разбиение внутри одной СУБД, шардирование — распределение по разным серверам для масштабирования.

| Параметр | Шардирование | Партиционирование |
|---|---|---|
| Количество серверов | Несколько | Обычно один |
| Масштабирование | Горизонтальное | Логическое |
| Распределение данных | Между серверами | Внутри одной БД |
| Производительность | Выше при больших нагрузках | Ограничена ресурсами сервера |
Партиционирование помогает структурировать данные внутри базы данных, а шардирование используется для масштабирования инфраструктуры.
Шардирование и репликация: в чем разница
Шардирование и репликация часто используются вместе, однако они решают разные задачи.
Шардирование предназначено для масштабирования и распределения данных между серверами, а репликация создает копии данных для повышения отказоустойчивости и доступности системы.
| Параметр | Шардирование | Репликация |
|---|---|---|
| Основная цель | Масштабирование | Отказоустойчивость |
| Хранение данных | Частями | Полные копии |
| Нагрузка | Распределяется | Дублируется |
| Производительность | Увеличивается | Повышается доступность |
| Количество данных | Разделяется | Копируется |
На практике крупные распределенные системы часто используют одновременно и шардирование, и репликацию.
Сложности шардирования: распределённые транзакции и JOIN
Основные проблемы — выполнение запросов, затрагивающих несколько шардов (cross-shard queries), и обеспечение атомарности операций (ACID).
JOIN между шардами: Стандартные JOIN становятся невозможными или очень медленными. Решения:
- Денормализация данных (хранить связанные данные в одном шарде).
- Выполнять JOIN на уровне приложения (получить данные из разных шардов и объединить в коде).
- Использовать глобальные справочные таблицы (реплицировать их на каждый шард).
Распределённые транзакции (ACID): Обеспечение атомарности операций, изменяющих данные на нескольких шардах — сложная задача. Подходы:
- Двухфазный коммит (2PC): Обеспечивает атомарность, но медленный и снижает доступность.
- Сага (Saga pattern): Разбивает транзакцию на цепочку локальных транзакций с компенсирующими действиями. Более гибкий, но требует детального проектирования.
- Использование очередей и eventual consistency: Вместо немедленной согласованности — согласованность в конечном счёте (подход многих NoSQL систем).
Выбор подхода зависит от требований к согласованности и доступности (CAP-теорема).
Преимущества и недостатки шардирования
Шардирование даёт огромный выигрыш в производительности и масштабируемости, но требует серьёзных архитектурных изменений и усложняет поддержку.
| Преимущества | Недостатки |
|---|---|
| ✅ Горизонтальное масштабирование — можно добавлять серверы | ❌ Сложность реализации, требуется переработка кода |
| ✅ Высокая производительность за счёт параллельной обработки | ❌ Более сложные запросы (JOIN между шардами) |
| ✅ Балансировка нагрузки между узлами | ❌ Усложнение мониторинга и администрирования |
| ✅ Повышенная отказоустойчивость (отказ одного узла не убивает всю систему) | ❌ Необходимость мониторинга сложность транзакций (распределённые ACID) |
| ✅ Рост без замены оборудования | ❌ Сложность миграции данных при изменении ключа |
Как сделать шардирование
Для внедрения шардирования необходимо определить стратегию распределения данных и подготовить архитектуру базы данных. Ключевые этапы: выбор ключа, стратегия, миграция данных, настройка маршрутизации и решардинга.
- Анализ запросов и выбор ключа (Shard Key). Изучите, как приложение обращается к данным.
- Выбор стратегии. Горизонтальное, вертикальное, консистентное — в зависимости от задачи.
- Проектирование количества шардов. Учитывайте будущий рост (лучше начать с большего числа виртуальных шардов).
- Реализация маршрутизации. Через middleware (например, ShardingSphere) или в коде приложения.
- Миграция данных (самый сложный этап):
- Cutover-стратегия: перевод системы на шардирование в один момент (требует остановки записи).
- Постепенный перенос: двойная запись в старую и новую схему, затем переключение трафика (меньше простоев).
- Настройка репликации для каждого шарда (отказоустойчивость).
- Решардинг (изменение количества шардов):
- При использовании консистентного хеширования или виртуальных шардов — минимальные перемещения.
- Планируйте решардинг заранее, чтобы избежать простоя.
- Мониторинг и нагрузочное тестирование. Проверяйте равномерность распределения, латентность, нагрузку на узлы.
Для новичков рекомендуем начать с готового решения (ShardingSphere, Vitess), чтобы сократить время разработки.
Итак основные этапы:
| Этап | Цель |
|---|---|
| Выбор ключа шардирования | Равномерное распределение данных |
| Создание шардов | Масштабирование инфраструктуры |
| Маршрутизация запросов | Поиск нужного узла |
| Балансировка нагрузки | Оптимизация производительности |
| Репликация | Повышение отказоустойчивости |
| Мониторинг | Контроль состояния кластера |
Где используется шардирование: инструменты и реальные кейсы
Шардирование применяется в высоконагруженных системах с большими объёмами данных — от интернет-магазинов и социальных сетей до аналитических платформ и распределённых хранилищ. Для реализации шардирования используют встроенные механизмы СУБД, middleware и специализированные расширения.
Инструменты для шардирования
| Инструмент / СУБД | Особенность | Где применяется |
|---|---|---|
| Apache ShardingSphere | Middleware для MySQL, PostgreSQL, Oracle | Крупные интернет-проекты, корпоративные системы |
| Vitess | Middleware для MySQL (используется в YouTube) | Высоконагруженные веб-приложения |
| MongoDB | Встроенное шардирование (нативное) | Распределённое хранение документов |
| ClickHouse | Аналитическая СУБД с шардированием (в Яндекс.Облаке) | Аналитика больших данных, временные ряды |
| PostgreSQL (с расширениями) | Масштабирование через pg_shardman или Citus | Корпоративные БД, финтех |
| MySQL | Шардирование через middleware или NDB Cluster | Интернет-магазины, CRM, соцсети |
| Redis Cluster | Консистентное хеширование для in-memory хранилищ | Высокоскоростное кеширование, сессии |
| Cassandra | Распределённая колоночная БД с шардированием по умолчанию | Распределённые системы с высокой нагрузкой |
Реальные кейсы из индустрии
ВКонтакте использует шардирование по идентификатору пользователя (
user_id) для распределения данных о сообщениях и профилях. Это позволяет обрабатывать миллиарды записей и сохранять отказоустойчивость при нагрузке.Яндекс.Облако (ClickHouse) автоматически шардирует аналитические данные по датам и ключам для быстрой обработки временных рядов. Это основа для систем мониторинга и бизнес-аналитики.
Ozon применяет шардирование для таблиц заказов и товаров, распределяя нагрузку между сотнями серверов и обеспечивая стабильную работу в пиковые нагрузки (например, в дни распродаж).
Заключение: 3 главных правила шардирования
Шардирование — мощный, но сложный инструмент. Его стоит применять только при реальной необходимости, тщательно выбирая ключ и стратегию.
- Правильный ключ — залог успеха. Анализируйте запросы, чтобы выбрать ключ, который обеспечит равномерное распределение и эффективную маршрутизацию.
- Не забывайте о репликации. Каждый шард должен быть реплицирован, чтобы обеспечить отказоустойчивость.
- Мониторьте и тестируйте. Сложность распределённой системы требует постоянного контроля за нагрузкой, размером шардов и задержками.
Если ваш проект перерос возможности одного сервера — шардирование станет спасательным кругом. Начните с малого: используйте готовые middleware, поэтапно переносите данные и всегда держите план отката.
Читайте также:
Часто задаваемые вопросы (FAQ) о шардировании
Что такое шардирование базы данных?
Шардирование — это разделение БД на независимые части (шарды), хранящиеся на разных серверах для горизонтального масштабирования.
Чем шардирование отличается от партиционирования?
Партиционирование разбивает таблицы внутри одного сервера, а шардирование распределяет их по нескольким серверам.
Что такое ключ шардирования и как его выбрать?
Ключ — поле, определяющее шард. Выбирайте по критериям: равномерность, селективность, стабильность.
Что такое консистентное шардирование?
Это алгоритм распределения данных (консистентное хеширование), минимизирующий перемещение данных при добавлении/удалении узлов.
Как выполнять JOIN между шардами?
JOIN между шардами сложны. Используйте денормализацию, объединение на уровне приложения или глобальные справочные таблицы.
Как обеспечить ACID-транзакции при шардировании?
Используйте двухфазный коммит (2PC) для строгой согласованности или паттерн Saga для eventual consistency.
Когда шардирование не нужно?
При небольших объёмах данных (до нескольких миллионов записей) или низкой нагрузке — достаточно оптимизации и репликации.
Какие инструменты помогают реализовать шардирование?
Apache ShardingSphere, Vitess, MongoDB, ClickHouse, Postgres Pro Shardman, Redis Cluster.
Как мигрировать существующую БД на шардирование?
Стратегии: cutover (остановка записи) или постепенный перенос с двойной записью. Требует тщательного тестирования.
Как выбрать между горизонтальным и вертикальным шардированием?
Горизонтальное — для масштабирования по строкам (большое количество записей). Вертикальное — для разделения функционала (разные сервисы).