Правильно выстроенные KPI в Service Desk позволяют не просто измерять нагрузку на сотрудников, но и объективно оценивать качество ИТ-обслуживания в масштабах всей компании. В этой статье мы разбираем 10 фундаментальных принципов построения системы показателей, которые превращают поддержку из центра затрат в эффективный инструмент бизнеса. Вы узнаете, как сбалансировать скорость и качество сервиса, внедрив ключевые метрики от MTTR и SLA до индексов клиентского опыта CSAT и CES.
Краткое содержание
Как работают KPI в Service Desk
KPI (Key Performance Indicators) — это количественно измеримые индикаторы, которые позволяют оценить эффективность выполнения конкретных задач и степень достижения поставленных целей. В контексте службы поддержки эти показатели помогают понять, насколько качественно система справляется с нагрузкой и удовлетворяет потребности пользователей.
Количество закрытых заявок в конце месяца часто создает иллюзию продуктивной работы. Однако сухая статистика «закрытых тикетов» — это не показатель успеха, а лишь объем проделанной работы. Если из тысячи заявок половина была решена со второго раза, а пользователи остались недовольны качеством ответов, такая производительность становится убыточной для компании.
Настоящая роль KPI заключается в том, чтобы стать связующим звеном между техническими процессами ИТ-департамента и стратегическими целями бизнеса. Правильно выстроенная система метрик переводит работу инженеров с языка «инцидентов» на язык «ценности»: предотвращение простоев, экономия времени сотрудников и поддержание высокого уровня клиентского сервиса.
Для построения такой системы мы выделили 10 базовых принципов эффективности, которые подробно разберем в этой статье:
- Привязка к процессам — фокус на вкладе в бизнес-результаты.
- Баланс скорости и качества — поиск «золотой середины» между временем и результатом.
- Ориентация на UX — учет субъективной удовлетворенности пользователей.
- Контроль SLA и OLA — соблюдение договорных обязательств.
- Прозрачность — создание понятной и измеримой системы данных.
- Сегментация — работа с приоритетами и критичностью заявок.
- Предотвращение — акцент на проактивном решении проблем.
- Эффективность команды — анализ нагрузки и выгорания сотрудников.
- Автоматизация — развитие инструментов самообслуживания.
- Непрерывное улучшение — использование метрик для постоянной оптимизации сервиса.
Стратегический подход к выбору метрик KPI
Прежде чем внедрять десятки показателей, необходимо определить фундаментальные правила, по которым сервисная система будет приносить пользу компании. Эти принципы помогают сбалансировать нагрузку на команду и ожидания пользователей, превращая поддержку из «центра затрат» в инструмент роста эффективности.
1. Привязка KPI к сервисным процессам
KPI должны наглядно отражать вклад службы поддержки в общую продуктивность бизнеса. Важно отслеживать не просто факт выполнения работы, а то, как она влияет на доступность ключевых сервисов компании и качество взаимодействия с клиентами.
- Доля инцидентов, влияющих на доступность сервисов (%): показывает, какой процент проблем напрямую парализует работу отделов или внешних пользователей.
- Простои из-за ИТ-инцидентов: суммарное время, в течение которого бизнес-процессы были остановлены. Эта метрика помогает оценить реальный финансовый ущерб от технических сбоев.
2. Баланс скорости и качества
В погоне за скоростью важно не потерять качество решения задачи. Высокая скорость закрытия бесполезна, если пользователю приходится возвращаться с той же проблемой снова.
- Среднее время решения (MTTR): основной показатель оперативности команды.
- Уровень возвращенных обращений (% Reopen Rate): критическая метрика качества. Высокий процент переоткрытых заявок сигнализирует о поверхностном подходе к решению проблем.
- Решение вопроса в рамках одного ответа (FCR): «высший пилотаж» поддержки — когда клиент получает полное решение при первом же обращении без уточняющих вопросов и переключений.

Контроль обращений клиентов в ELMA365 Service Desk
3. Ориентация на пользовательский опыт (UX)
Субъективное восприятие сервиса зачастую важнее технических отчетов. Даже при соблюдении всех сроков клиент может остаться недоволен манерой общения или сложностью подачи заявки.
- Индекс удовлетворенности клиентов (CSAT): прямая оценка пользователем конкретного взаимодействия с поддержкой.
- Индекс клиентских усилий (CES): метрика, показывающая, насколько легко клиенту было получить помощь. Чем меньше действий (звонков, писем, уточнений) потребовалось для результата, тем выше лояльность.
4. Контроль SLA и OLA
Соблюдение официальных договоренностей — это фундамент доверия между сервисной службой и бизнесом. Четкие метрики позволяют понять, справляется ли решение с установленным регламентом.
- % соблюдения SLA: доля заявок, решенных без нарушения нормативных сроков.
- Время реакции (First Response Time): время с момента подачи заявки до первого содержательного ответа специалиста, которое критически важно для психологического комфорта пользователя.
| Метрика | Что измеряет | Зачем отслеживать |
|---|
| MTTR | Среднее время решения | Оценка скорости работы команды |
| FCR | Решение при первом контакте | Экономия времени пользователя и ресурсов поддержки |
| Reopen Rate | Процент переоткрытых заявок | Контроль качества — не закрываются ли заявки «для галочки» |
| CSAT | Уровень удовлетворенности | Понимание эмоционального фона и качества сервиса |
| CES | Индекс клиентских усилий | Оценка простоты и удобства взаимодействия с системой |
| SLA Compliance | Процент соблюдения регламента | Гарантия выполнения обязательств перед бизнесом |
KPI для операционного управления и прозрачности
На операционном уровне эффективность системы зависит от точности данных и умения распределять ресурсы. Здесь KPI помогают выявить проблемы в работе конкретных групп поддержки и объективно оценить сложность поступающих задач. Это позволяет не просто фиксировать факты, а управлять процессом в режиме реального времени.
5. Прозрачность и измеримость
Любое управленческое решение должно основываться на достоверных цифрах. Все показатели должны быть прозрачны и доступны для анализа в любой момент, чтобы исключить субъективность в оценке работы специалистов.
- Доля тикетов с низкой оценкой (%): позволяет быстро локализовать проблемные зоны. Если конкретный тип заявок или специалист систематически получают низкие баллы, это сигнал к пересмотру инструкций или проведению дополнительного обучения.

Статистика выполненных и рабочих задач в ELMA365 Service Desk
6. Сегментация и приоритизация
Эффективное решение не может обрабатывать все запросы в порядке общей очереди. Важно разделять метрики в зависимости от критичности инцидента для бизнеса, чтобы фокус команды всегда оставался на самых приоритетных задачах.
- MTTR по приоритетам (P1, P2, P3): время решения критической аварии (P1) должно быть в разы меньше, чем время выполнения плановой консультации. Разделение этого показателя дает реальную картину оперативности.
- Количество критических инцидентов: мониторинг числа самых тяжелых сбоев, которые напрямую влияют на финансовые показатели или репутацию компании.
7. Фокус на предотвращении
Service Desk стремится не к тому, чтобы быстрее чинить поломки, а к тому, чтобы они не возникали. Переход от реактивной модели («сломалось — починили») к проактивной позволяет значительно снизить нагрузку на инженеров.
- Количество повторяющихся инцидентов: если одна и та же проблема возникает еженедельно, значит, устраняется симптом, а не причина. Снижение этого показателя говорит о качественной работе с проблемами.
- Количество известных ошибок (Known Errors): наличие наполненной базы знаний с описанными решениями типовых проблем позволяет решать инциденты быстрее или вовсе избегать их возникновения.
8. Эффективность команды
Важно найти баланс между высокой продуктивностью и предотвращением выгорания сотрудников. Метрики производительности помогают грамотно распределять нагрузку внутри отделов.
- Тикеты на группу поддержки / Время обработки: помогает понять, какие линии или отделы перегружены, а где есть свободный ресурс.
- Utilization rate (% загрузки): процент рабочего времени, затраченного непосредственно на решение задач. Слишком высокий показатель (близкий к 100%) ведет к ошибкам и увольнениям, слишком низкий — к неэффективному использованию бюджета.
| Категория | Метрика | Цель мониторинга |
|---|
| Приоритизация | MTTR по уровням P1–P3 | Гарантия быстрой реакции на критические сбои |
| Проактивность | Доля повторяющихся инцидентов | Снижение общего потока заявок за счет устранения причин |
| Нагрузка | Utilization rate (%) | Профилактика выгорания и оптимизация численности штата |
| Прозрачность | % обращений с негативной оценкой | Выявление слабых мест в процессах или компетенциях |
KPI технологического развития и оптимизации
KPI автоматизации в Service Desk позволяют оцифровать выгоду от внедрения новых инструментов и отследить культуру непрерывного совершенствования процессов. Иными словами — насколько в действительности компании будет выгодно внедрить ту или иную технологию в свою постоянную работу.
9. Автоматизация и самообслуживание
Метрики этого блока показывают, насколько эффективно решение справляется с задачей разгрузки «человеческого» ресурса. Без этих KPI невозможно оценить окупаемость вложений в чат-ботов, порталы самообслуживания и интеллектуальные алгоритмы.
- Доля обращений через self-service портал: этот индикатор демонстрирует уровень цифровой грамотности пользователей и качество базы знаний. Чем выше процент, тем меньше рутинных обращений падает на почту и телефон поддержки.
- Процент автоматизированных запросов (%): KPI, измеряющий долю задач, которые система закрыла полностью без участия инженера (например, автоматическая выдача доступа или создание учетной записи).
- Снижение нагрузки на 1-ю линию: показатель, отражающий «эффективность фильтрации». Он измеряет, сколько потенциальных тикетов было решено на этапе поиска по базе знаний или общения с ботом.
10. Непрерывное улучшение (Continuous Improvement)
Здесь KPI выступают в роли лакмусовой бумажки для проверки любых организационных изменений. Это не просто отчетность, а инструмент для замера «дельты» между старым и новым качеством сервиса.
- Сравнительный анализ (квартал к кварталу): измерение того, как изменились MTTR или CSAT после внедрения новой функции или изменения скрипта. Это позволяет понять, действительно ли изменения привели к улучшению, а не просто усложнили процесс.
- Процент предотвращённых инцидентов: KPI проактивности, который оценивает работу по управлению проблемами. Если количество массовых сбоев снижается относительно прошлых периодов, значит, система работает на опережение.
| Направление | Ключевая метрика (KPI) | Что именно мы измеряем |
|---|
| Самообслуживание | Self-service Rate | Эффективность портала и базы знаний |
| Роботизация | % Auto-resolved tickets | Долю процессов, работающих полностью без участия людей |
| Динамика | Delta KPI (QoQ) | Реальный эффект от внедрения новых технологий в цифрах |
| Оптимизация | Shift-Left Rate | Насколько успешно сложные задачи превращаются в простые инструкции |
Как ELMA365 Service Desk автоматизирует и отслеживает KPI: 10 принципов эффективного сервиса
KPI в Service Desk — это не просто цифры в отчёте. Это рабочий инструмент, который помогает понять, насколько поддержка реально влияет на устойчивость процессов, качество сервиса и скорость работы бизнеса.
В ELMA365 Service Desk показатели не живут отдельно от процессов. Метрики автоматически собираются на каждом этапе работы с обращением: от регистрации заявки до оценки результата пользователем. За счёт этого руководитель видит не набор разрозненных чисел, а целостную картину: где сервис работает стабильно, где накапливаются риски и какие изменения действительно дают эффект.
Дополнительная ценность в том, что KPI можно быстро адаптировать под особенности компании: за счёт low-code подхода команды настраивают дашборды, отчёты и срезы аналитики под свою модель процессов — без сложной доработки системы.
1. Привязка к процессам — смотреть на влияние, а не только на поток заявок
Количество обращений само по себе редко даёт полезный вывод. Намного важнее понимать, какие процессы стоят за этими заявками и где именно возникают системные сбои.
В ELMA365 Service Desk можно анализировать обращения в разрезе услуг, групп поддержки, каналов коммуникации, типов запросов и их приоритета. Это помогает увидеть, например, что рост заявок связан не с перегрузкой поддержки, а с нестабильностью конкретного процесса — например, закупок, HR-сервиса или ИТ-инфраструктуры.
Метрики:
- количество обращений по услугам;
- распределение по типам обращений;
- количество инцидентов по услугам;
- время недоступности услуг;
- процент доступности услуги в рабочее время.
За счёт этого Service Desk становится не системой учёта тикетов, а инструментом управления устойчивостью процессов.
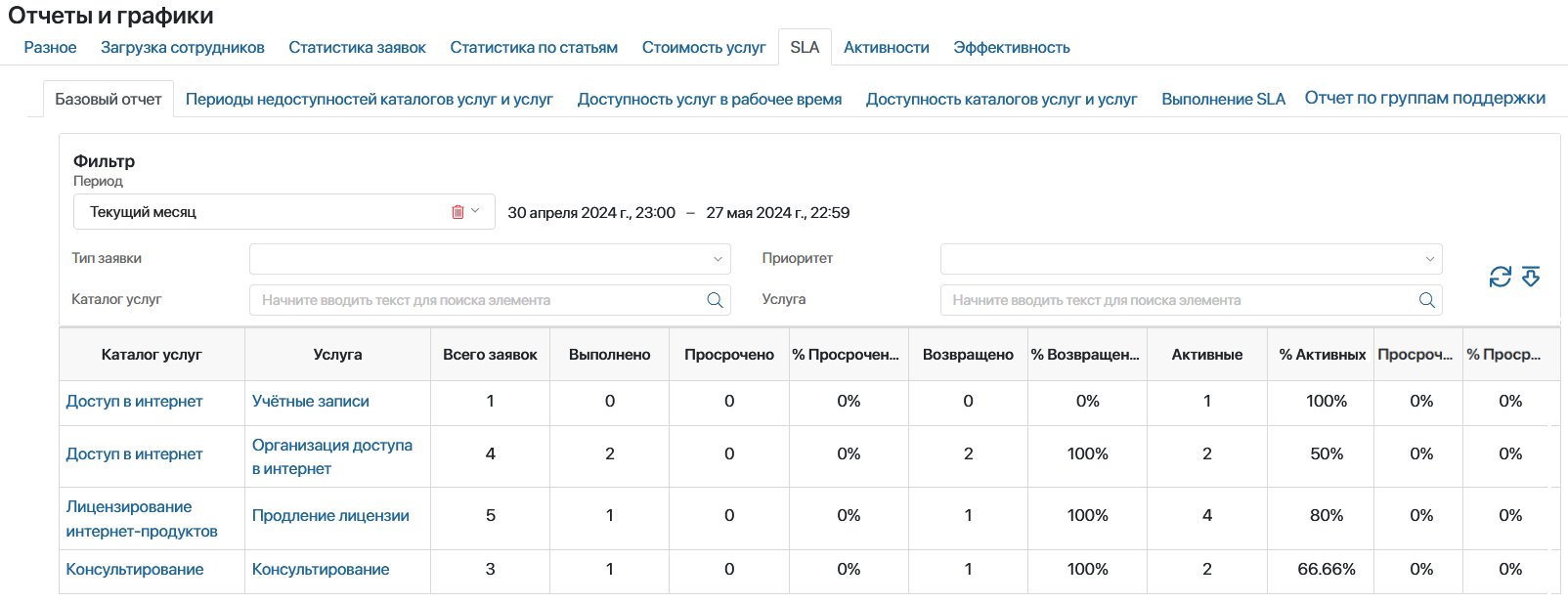
Отчеты и графики
2. Баланс скорости и качества — быстро закрыть не значит решить
Одна из типовых ошибок в KPI Service Desk — смотреть только на скорость.
Заявка может быть закрыта формально быстро, но если пользователь возвращается с той же проблемой, бизнес получает повторные потери времени и ресурсов.
ELMA365 Service Desk помогает видеть полный цикл обращения: где происходит задержка, сколько времени заявка проводит в статусах и насколько решение оказалось устойчивым.
Метрики:
- среднее время первой реакции;
- среднее время решения;
- время в каждом статусе;
- повторные обращения;
- возвращённые заявки;
- доля обращений, закрытых в срок.
Такой подход помогает оценивать не только производительность, но и зрелость сервисного процесса.
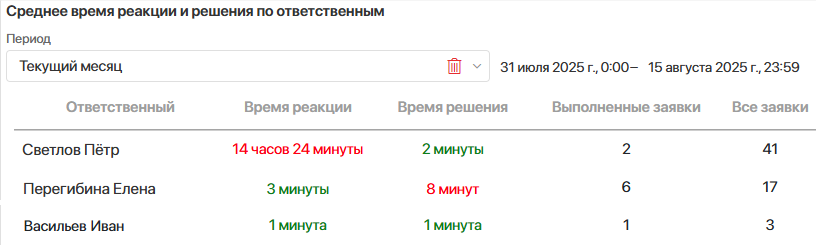
Среднее время реакции
3. Ориентация на UX — оценивать сервис глазами пользователя
Поддержка эффективна только тогда, когда это чувствует сам пользователь.
Поэтому в ELMA365 Service Desk можно автоматически собирать обратную связь после закрытия обращения и анализировать её в разрезе услуг, операторов и каналов.
Метрики:
- средняя оценка оператора;
- CSAT;
- доля положительных отзывов;
- доля негативных оценок;
- удовлетворённость по услугам и каналам.
Это помогает улучшать не только скорость работы, но и сам пользовательский опыт взаимодействия с сервисом.
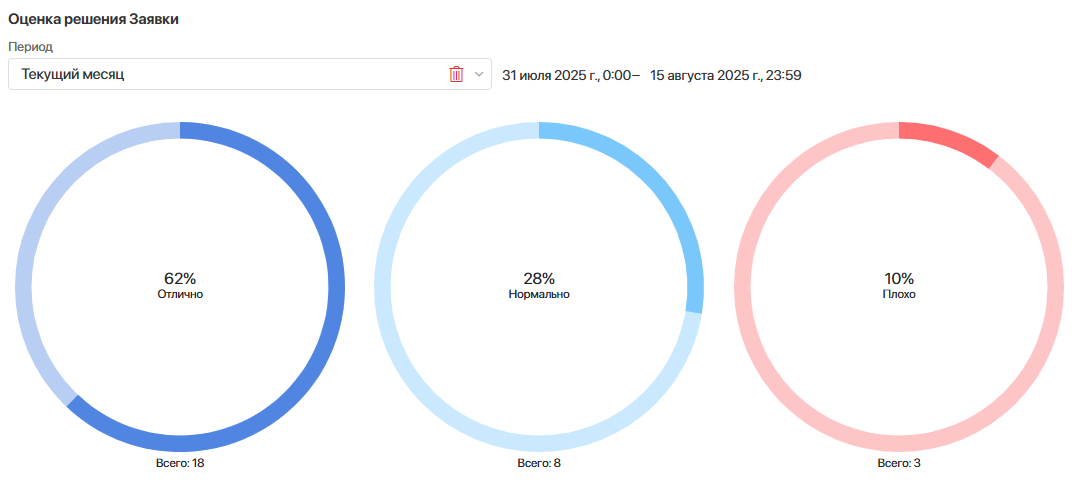
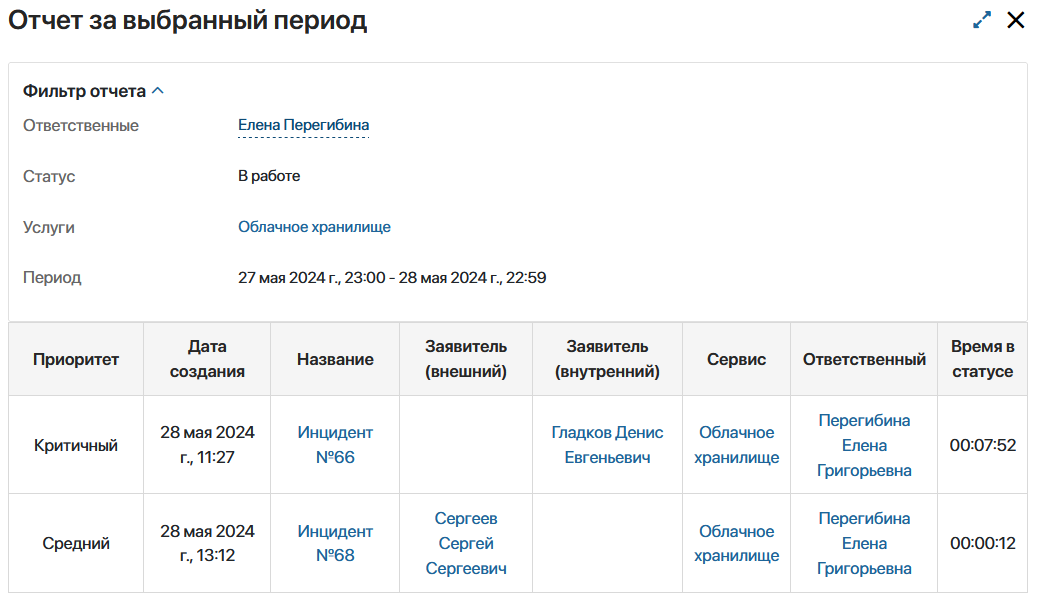
Отчет за выбранный период
4. Контроль SLA и OLA — прозрачные обязательства перед бизнесом
Для бизнеса важна не просто скорость, а предсказуемость.
ELMA365 Service Desk автоматически контролирует SLA и внутренние OLA между командами, заранее сигнализирует о рисках нарушения сроков и помогает быстро локализовать узкое место в процессе.
Метрики:
- время реакции;
- время решения;
- процент выполненных в срок SLA;
- количество нарушений SLA;
- SLA по сотрудникам;
- SLA по услугам;
- SLA по типам заявок.
Это позволяет выстраивать понятные сервисные обязательства между ИТ, внутренними заказчиками и бизнес-функциями.
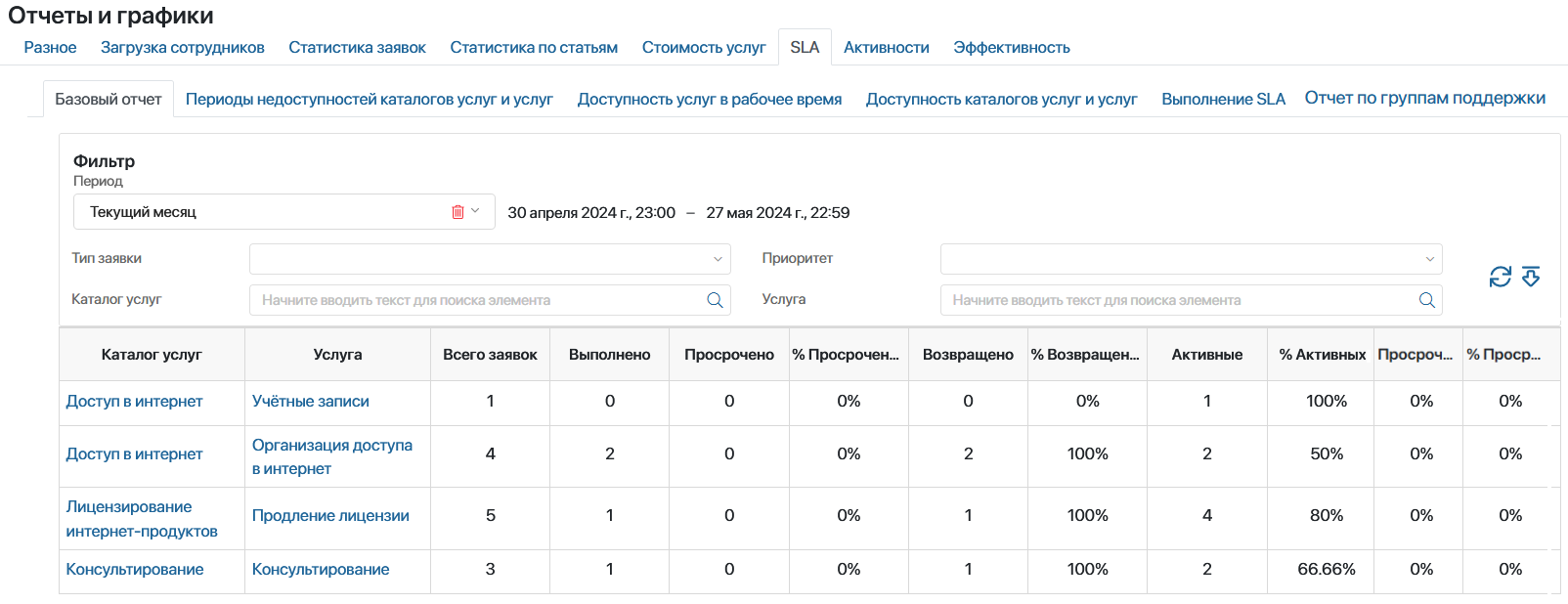
Отчет за выбранный период
5. Прозрачность — единая точка принятия решений
Когда данные о сервисе живут в разных таблицах и отчётах, управлять качеством становится сложно.
В ELMA365 Service Desk все показатели собираются в едином аналитическом контуре: обращения, SLA, загрузка, активности, пользовательские оценки и доступность сервисов.
Метрики:
- активные заявки;
- закрытые обращения;
- динамика обращений;
- статусная воронка;
- SLA-отчёты;
- отчёты по нагрузке команды поддержки.
Дашборды можно быстро адаптировать под роль: отдельный срез для руководителя поддержки, CIO или владельца бизнес-сервиса.
Отчет за выбранный период
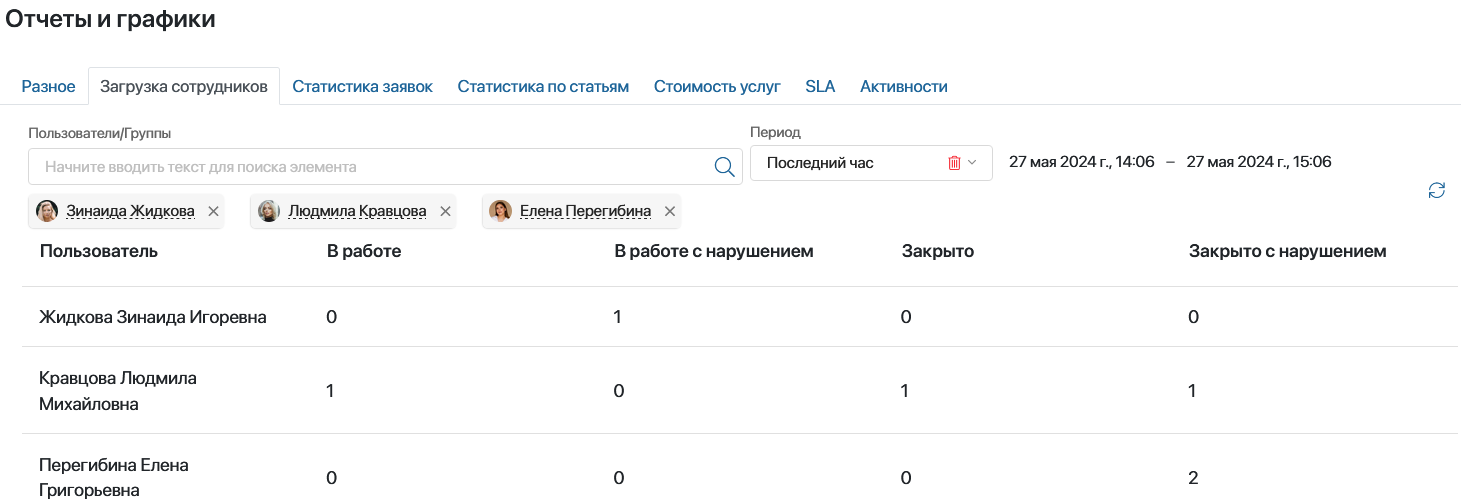
6. Сегментация — разные KPI для разных уровней критичности
Критичный инцидент и типовой запрос нельзя измерять одинаково.
ELMA365 Service Desk позволяет выстраивать KPI по приоритетам, критичности и влиянию на бизнес-процессы.
Метрики:
- распределение по приоритетам;
- количество P1/P2 инцидентов;
- время решения критичных заявок;
- SLA по high-priority обращениям;
- доля просроченных критичных инцидентов.
Это особенно важно для компаний с несколькими сервисными линиями и высоким уровнем операционных рисков.
Отчет за выбранный период
7. Предотвращение — снижать количество инцидентов, а не только решать их
Зрелый Service Desk должен работать не только в реактивной, но и в проактивной модели.
ELMA365 Service Desk помогает выявлять повторяемые проблемы и работать с первопричинами.
Метрики:
- повторные обращения;
- частота инцидентов по категориям;
- причины сбоев;
- повторяемость инцидентов;
- динамика аварий по сервисам;
- формирование базы знаний.
На основе этих данных можно менять процессы, обновлять базу знаний и устранять системные узкие места.
Отчет за выбранный период
8. Эффективность команды — баланс нагрузки и результата
Для качественного сервиса важно понимать реальную загруженность специалистов. Перегрузка ведет к выгоранию и ошибкам, а недогрузка — к неэффективному использованию бюджета.
ELMA365 Service Desk предоставляет прозрачную аналитику по работе каждого сотрудника и группы поддержки в целом.
Метрики:
- количество закрытых заявок на сотрудника;
- среднее время обработки обращения специалистом;
- утилизация (загрузка) команды;
- рейтинг операторов по оценкам пользователей;
- количество активных задач в работе у инженера.
Это позволяет руководителю гибко перераспределять ресурсы и вовремя замечать потребность в расширении штата или дополнительном обучении.
Отчет за выбранный период
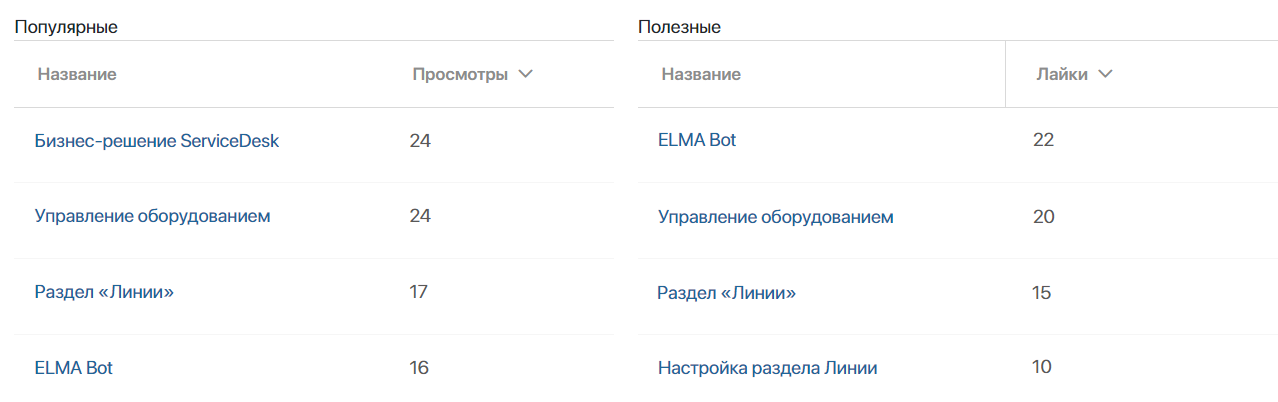
9. Автоматизация — развивать self-service на основе данных
Самообслуживание должно снижать нагрузку не «на бумаге», а в реальной операционной работе.
ELMA365 Service Desk позволяет измерять, насколько портал, база знаний и автоматические маршруты действительно сокращают количество типовых обращений.
Метрики:
- доля обращений через портал;
- популярность статей;
- использование базы знаний;
- self-service resolution rate;
- снижение нагрузки на первую линию.
Благодаря low-code настройке такие сценарии можно быстро развивать по мере роста сервисной функции.
Отчет за выбранный период
10. Непрерывное улучшение — KPI как инструмент развития сервиса
Метрики имеют смысл только тогда, когда по ним принимаются решения.
ELMA365 Service Desk помогает отслеживать динамику изменений и быстро видеть эффект от новых регламентов, перераспределения нагрузки или автоматизации.
Метрики:
- динамика SLA;
- изменение времени решения;
- рост CSAT;
- снижение повторных обращений;
- рост доступности сервисов.
Именно здесь KPI становятся инструментом постоянного улучшения сервиса, а не просто частью отчётности.
Как внедрить KPI: пошаговый алгоритм
Внедрение системы показателей — это не разовое действие, а циклический процесс. Чтобы метрики стали реальным инструментом управления, а не формальностью в отчетах, важно пройти путь от технической подготовки до формирования культуры ответственности внутри команды.
Шаг 1. Выбор системы учета и автоматизации
Первым делом необходимо убедиться, что ваша текущая сервисная система способна собирать данные в реальном времени. Если вы фиксируете время решения вручную в таблицах, риск человеческой ошибки и манипуляции данными будет слишком высок. Современное решение должно автоматически фиксировать каждое действие: от момента поступления заявки до финальной оценки пользователя.
Шаг 2. Определение базовых показателей (Baseline)
Не стоит пытаться внедрить все 20–30 известных метрик сразу. Начните с «золотого стандарта»:
- Соблюдение SLA (скорость).
- Уровень удовлетворенности CSAT (качество).
- Нагрузка на специалистов (количество заявок).
Замерьте эти показатели в течение месяца без установления планов, чтобы понять ваши текущие возможности — это и будет ваша точка отсчета.
Шаг 3. Установка целевых и пороговых значений
На основе полученных данных установите реалистичные цели.
- Целевое значение: уровень, к которому мы стремимся (например, 95% соблюдения SLA).
- Пороговое (критическое) значение: уровень, ниже которого работа службы считается неудовлетворительной (например, менее 80% SLA).
Важно, чтобы эти цифры были согласованы с бизнесом: понимает ли руководство, почему MTTR составляет именно 4 часа, и готово ли оно инвестировать в его сокращение.
Шаг 4. Настройка дашбордов и отчетности
Метрики должны быть «живыми». Руководитель службы поддержки должен видеть динамику KPI на интерактивных дашбордах в режиме реального времени, а не в конце квартала. Прозрачность данных внутри команды также полезна: когда сотрудники видят свой вклад в общие показатели (например, личный рейтинг FCR), это создает здоровую мотивацию.
Шаг 5. Регулярный пересмотр и адаптация
Бизнес меняется, и KPI должны меняться вместе с ним. Раз в квартал или полугодие проводите ревизию:
- Не стали ли показатели слишком легкими для достижения?
- Не гонится ли команда за скоростью в ущерб качеству?
- Помогают ли выбранные метрики достигать целей компании?
Заключение
Эффективная система KPI в Service Desk — это живой механизм, который переводит работу технической поддержки на язык цифр и бизнес-ценностей. Главное помнить: показатели существуют не для того, чтобы контролировать каждый шаг сотрудника, а для того, чтобы вовремя замечать отклонения в процессах и находить точки роста. Начиная с базовых метрик скорости и постепенно переходя к показателям автоматизации и проактивности, вы превратите свою службу поддержки в мощный инструмент развития компании.




